monocular
Papers with tag monocular
2022
- Learned Vertex Descent: A New Direction for 3D Human Model FittingEnric Corona, Gerard Pons-Moll, Guillem Alenyà, and Francesc Moreno-NoguerIn 2022
We propose a novel optimization-based paradigm for 3D human model fitting onimages and scans. In contrast to existing approaches that directly regress theparameters of a low-dimensional statistical body model (e.g. SMPL) from inputimages, we train an ensemble of per-vertex neural fields network. The networkpredicts, in a distributed manner, the vertex descent direction towards theground truth, based on neural features extracted at the current vertexprojection. At inference, we employ this network, dubbed LVD, within agradient-descent optimization pipeline until its convergence, which typicallyoccurs in a fraction of a second even when initializing all vertices into asingle point. An exhaustive evaluation demonstrates that our approach is ableto capture the underlying body of clothed people with very different bodyshapes, achieving a significant improvement compared to state-of-the-art. LVDis also applicable to 3D model fitting of humans and hands, for which we show asignificant improvement to the SOTA with a much simpler and faster method.
一种新的姿态估计的框架
human monocular 1p SMPL@inproceedings{LVD, title = {Learned Vertex Descent: A New Direction for 3D Human Model Fitting}, author = {Corona, Enric and Pons-Moll, Gerard and Alenyà, Guillem and Moreno-Noguer, Francesc}, year = {2022}, tags = {human, monocular, 1p, SMPL}, } - State of the Art in Dense Monocular Non-Rigid 3D ReconstructionEdith Tretschk, Navami Kairanda, Mallikarjun B R, Rishabh Dabral, Adam Kortylewski, Bernhard Egger, Marc Habermann, Pascal Fua, Christian Theobalt, and Vladislav GolyanikIn 2022
3D reconstruction of deformable (or non-rigid) scenes from a set of monocular2D image observations is a long-standing and actively researched area ofcomputer vision and graphics. It is an ill-posed inverse problem,since–without additional prior assumptions–it permits infinitely manysolutions leading to accurate projection to the input 2D images. Non-rigidreconstruction is a foundational building block for downstream applicationslike robotics, AR/VR, or visual content creation. The key advantage of usingmonocular cameras is their omnipresence and availability to the end users aswell as their ease of use compared to more sophisticated camera set-ups such asstereo or multi-view systems. This survey focuses on state-of-the-art methodsfor dense non-rigid 3D reconstruction of various deformable objects andcomposite scenes from monocular videos or sets of monocular views. It reviewsthe fundamentals of 3D reconstruction and deformation modeling from 2D imageobservations. We then start from general methods–that handle arbitrary scenesand make only a few prior assumptions–and proceed towards techniques makingstronger assumptions about the observed objects and types of deformations (e.g.human faces, bodies, hands, and animals). A significant part of this STAR isalso devoted to classification and a high-level comparison of the methods, aswell as an overview of the datasets for training and evaluation of thediscussed techniques. We conclude by discussing open challenges in the fieldand the social aspects associated with the usage of the reviewed methods.
值得一看的单目非刚性重建的综述
monocular reconstruction nonrigid review@inproceedings{2210.15664, title = {State of the Art in Dense Monocular Non-Rigid 3D Reconstruction}, author = {Tretschk, Edith and Kairanda, Navami and R, Mallikarjun B and Dabral, Rishabh and Kortylewski, Adam and Egger, Bernhard and Habermann, Marc and Fua, Pascal and Theobalt, Christian and Golyanik, Vladislav}, year = {2022}, tags = {monocular, reconstruction, nonrigid, review}, } - HiFECap: Monocular High-Fidelity and Expressive Capture of Human PerformancesYue Jiang, Marc Habermann, Vladislav Golyanik, and Christian TheobaltIn 2022
Monocular 3D human performance capture is indispensable for many applicationsin computer graphics and vision for enabling immersive experiences. However,detailed capture of humans requires tracking of multiple aspects, including theskeletal pose, the dynamic surface, which includes clothing, hand gestures aswell as facial expressions. No existing monocular method allows joint trackingof all these components. To this end, we propose HiFECap, a new neural humanperformance capture approach, which simultaneously captures human pose,clothing, facial expression, and hands just from a single RGB video. Wedemonstrate that our proposed network architecture, the carefully designedtraining strategy, and the tight integration of parametric face and hand modelsto a template mesh enable the capture of all these individual aspects.Importantly, our method also captures high-frequency details, such as deformingwrinkles on the clothes, better than the previous works. Furthermore, we showthat HiFECap outperforms the state-of-the-art human performance captureapproaches qualitatively and quantitatively while for the first time capturingall aspects of the human.
performance-capture monocular@inproceedings{HiFECap, title = {HiFECap: Monocular High-Fidelity and Expressive Capture of Human Performances}, author = {Jiang, Yue and Habermann, Marc and Golyanik, Vladislav and Theobalt, Christian}, year = {2022}, tags = {performance-capture, monocular}, } - AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose RegressionYabo Xiao, Xiaojuan Wang, Dongdong Yu, Kai Su, Lei Jin, Mei Song, Shuicheng Yan, and Jian ZhaoIn 2022
Multi-person pose estimation generally follows top-down and bottom-upparadigms. Both of them use an extra stage (\boldsymbole.g., humandetection in top-down paradigm or grouping process in bottom-up paradigm) tobuild the relationship between the human instance and corresponding keypoints,thus leading to the high computation cost and redundant two-stage pipeline. Toaddress the above issue, we propose to represent the human parts as adaptivepoints and introduce a fine-grained body representation method. The novel bodyrepresentation is able to sufficiently encode the diverse pose information andeffectively model the relationship between the human instance and correspondingkeypoints in a single-forward pass. With the proposed body representation, wefurther deliver a compact single-stage multi-person pose regression network,termed as AdaptivePose. During inference, our proposed network only needs asingle-step decode operation to form the multi-person pose without complexpost-processes and refinements. We employ AdaptivePose for both 2D/3Dmulti-person pose estimation tasks to verify the effectiveness of AdaptivePose.Without any bells and whistles, we achieve the most competitive performance onMS COCO and CrowdPose in terms of accuracy and speed. Furthermore, theoutstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates theeffectiveness and generalizability on 3D scenes. Code is available athttps://github.com/buptxyb666/AdaptivePose.
multi-person monocular pose-estimation@inproceedings{AdaptivePose++, title = {AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression}, author = {Xiao, Yabo and Wang, Xiaojuan and Yu, Dongdong and Su, Kai and Jin, Lei and Song, Mei and Yan, Shuicheng and Zhao, Jian}, year = {2022}, tags = {multi-person, monocular, pose-estimation}, } - Capturing and Animation of Body and Clothing from Monocular VideoYao Feng, Jinlong Yang, Marc Pollefeys, Michael J. Black, and Timo BolkartIn 2022
While recent work has shown progress on extracting clothed 3D human avatarsfrom a single image, video, or a set of 3D scans, several limitations remain.Most methods use a holistic representation to jointly model the body andclothing, which means that the clothing and body cannot be separated forapplications like virtual try-on. Other methods separately model the body andclothing, but they require training from a large set of 3D clothed human meshesobtained from 3D/4D scanners or physics simulations. Our insight is that thebody and clothing have different modeling requirements. While the body is wellrepresented by a mesh-based parametric 3D model, implicit representations andneural radiance fields are better suited to capturing the large variety inshape and appearance present in clothing. Building on this insight, we proposeSCARF (Segmented Clothed Avatar Radiance Field), a hybrid model combining amesh-based body with a neural radiance field. Integrating the mesh into thevolumetric rendering in combination with a differentiable rasterizer enables usto optimize SCARF directly from monocular videos, without any 3D supervision.The hybrid modeling enables SCARF to (i) animate the clothed body avatar bychanging body poses (including hand articulation and facial expressions), (ii)synthesize novel views of the avatar, and (iii) transfer clothing betweenavatars in virtual try-on applications. We demonstrate that SCARF reconstructsclothing with higher visual quality than existing methods, that the clothingdeforms with changing body pose and body shape, and that clothing can besuccessfully transferred between avatars of different subjects. The code andmodels are available at https://github.com/YadiraF/SCARF.
输入单目RGB视频与衣服的分割,输出一个单独的人体和衣服层,可驱动
clothed monocular@inproceedings{2210.01868, title = {Capturing and Animation of Body and Clothing from Monocular Video}, author = {Feng, Yao and Yang, Jinlong and Pollefeys, Marc and Black, Michael J. and Bolkart, Timo}, year = {2022}, tags = {clothed, monocular}, } - SelfNeRF: Fast Training NeRF for Human from Monocular Self-rotating VideoBo Peng, Jun Hu, Jingtao Zhou, and Juyong ZhangIn 2022
In this paper, we propose SelfNeRF, an efficient neural radiance field basednovel view synthesis method for human performance. Given monocularself-rotating videos of human performers, SelfNeRF can train from scratch andachieve high-fidelity results in about twenty minutes. Some recent works haveutilized the neural radiance field for dynamic human reconstruction. However,most of these methods need multi-view inputs and require hours of training,making it still difficult for practical use. To address this challengingproblem, we introduce a surface-relative representation based onmulti-resolution hash encoding that can greatly improve the training speed andaggregate inter-frame information. Extensive experimental results on severaldifferent datasets demonstrate the effectiveness and efficiency of SelfNeRF tochallenging monocular videos.
monocular neural-rendering@inproceedings{selfnerf, title = {SelfNeRF: Fast Training NeRF for Human from Monocular Self-rotating Video}, author = {Peng, Bo and Hu, Jun and Zhou, Jingtao and Zhang, Juyong}, year = {2022}, tags = {monocular, neural-rendering}, } - MonoNHR: Monocular Neural Human RendererHongsuk Choi, Gyeongsik Moon, Matthieu Armando, Vincent Leroy, Kyoung Mu Lee, and Gregory RogezIn 2022
Existing neural human rendering methods struggle with a single image inputdue to the lack of information in invisible areas and the depth ambiguity ofpixels in visible areas. In this regard, we propose Monocular Neural HumanRenderer (MonoNHR), a novel approach that renders robust free-viewpoint imagesof an arbitrary human given only a single image. MonoNHR is the first methodthat (i) renders human subjects never seen during training in a monocularsetup, and (ii) is trained in a weakly-supervised manner without geometrysupervision. First, we propose to disentangle 3D geometry and texture featuresand to condition the texture inference on the 3D geometry features. Second, weintroduce a Mesh Inpainter module that inpaints the occluded parts exploitinghuman structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, andHUMBI datasets show that our approach significantly outperforms the recentmethods adapted to the monocular case.
monocular neural-rendering@inproceedings{MonoNHR, title = {MonoNHR: Monocular Neural Human Renderer}, author = {Choi, Hongsuk and Moon, Gyeongsik and Armando, Matthieu and Leroy, Vincent and Lee, Kyoung Mu and Rogez, Gregory}, year = {2022}, tags = {monocular, neural-rendering}, }
-
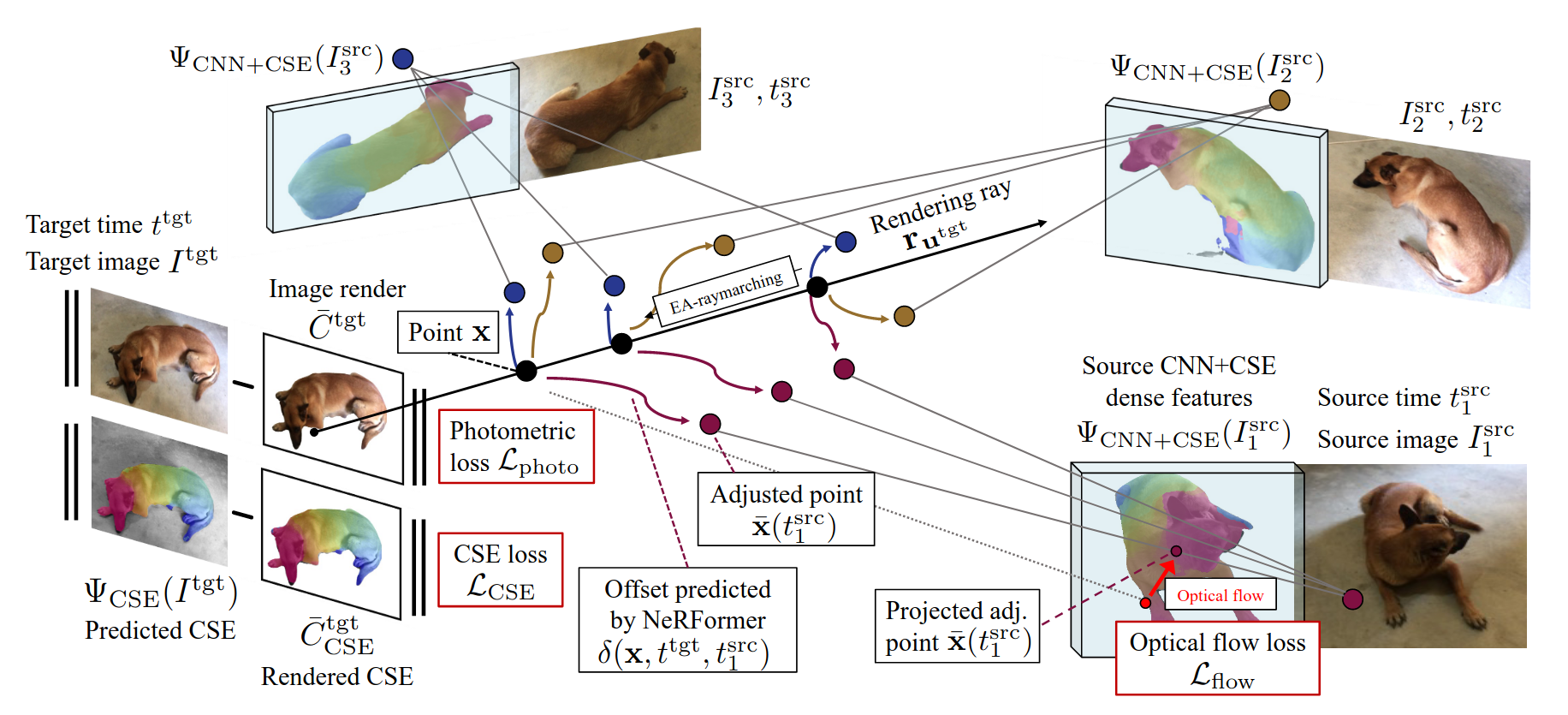 Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesSamarth Sinha, Roman Shapovalov, Jeremy Reizenstein, Ignacio Rocco, Natalia Neverova, Andrea Vedaldi, and David NovotnyIn 2022
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesSamarth Sinha, Roman Shapovalov, Jeremy Reizenstein, Ignacio Rocco, Natalia Neverova, Andrea Vedaldi, and David NovotnyIn 2022Obtaining photorealistic reconstructions of objects from sparse views isinherently ambiguous and can only be achieved by learning suitablereconstruction priors. Earlier works on sparse rigid object reconstructionsuccessfully learned such priors from large datasets such as CO3D. In thispaper, we extend this approach to dynamic objects. We use cats and dogs as arepresentative example and introduce Common Pets in 3D (CoP3D), a collection ofcrowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of thefirst large-scale datasets for benchmarking non-rigid 3D reconstruction "in thewild". We also propose Tracker-NeRF, a method for learning 4D reconstructionfrom our dataset. At test time, given a small number of video frames of anunseen object, Tracker-NeRF predicts the trajectories of its 3D points andgenerates new views, interpolating viewpoint and time. Results on CoP3D revealsignificantly better non-rigid new-view synthesis performance than existingbaselines.
提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.
monocular-video deformable-objects view-synthesis@inproceedings{Common_Pets, title = {Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories}, author = {Sinha, Samarth and Shapovalov, Roman and Reizenstein, Jeremy and Rocco, Ignacio and Neverova, Natalia and Vedaldi, Andrea and Novotny, David}, year = {2022}, tags = {monocular-video, deformable-objects, view-synthesis}, sida = {提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.}, }
2021
- Learning Temporal 3D Human Pose Estimation with Pseudo-LabelsArij Bouazizi, Ulrich Kressel, and Vasileios BelagiannisIn 2021
We present a simple, yet effective, approach for self-supervised 3D humanpose estimation. Unlike the prior work, we explore the temporal informationnext to the multi-view self-supervision. During training, we rely ontriangulating 2D body pose estimates of a multiple-view camera system. Atemporal convolutional neural network is trained with the generated 3Dground-truth and the geometric multi-view consistency loss, imposinggeometrical constraints on the predicted 3D body skeleton. During inference,our model receives a sequence of 2D body pose estimates from a single-view topredict the 3D body pose for each of them. An extensive evaluation shows thatour method achieves state-of-the-art performance in the Human3.6M andMPI-INF-3DHP benchmarks. Our code and models are publicly available at\urlhttps://github.com/vru2020/TM_HPE/.
输入一段序列的2D关键点,输出3Dpose,通过多视角的一致性来监督
human monocular 1p 3dpose self-supervised@inproceedings{temporal3d, title = {Learning Temporal 3D Human Pose Estimation with Pseudo-Labels}, author = {Bouazizi, Arij and Kressel, Ulrich and Belagiannis, Vasileios}, year = {2021}, tags = {human, monocular, 1p, 3dpose, self-supervised}, }