pose-estimation
Papers with tag pose-estimation
2022
- JRDB-Pose: A Large-scale Dataset for Multi-Person Pose Estimation and TrackingEdward Vendrow, Duy Tho Le, and Hamid RezatofighiIn 2022
Autonomous robotic systems operating in human environments must understandtheir surroundings to make accurate and safe decisions. In crowded human sceneswith close-up human-robot interaction and robot navigation, a deepunderstanding requires reasoning about human motion and body dynamics over timewith human body pose estimation and tracking. However, existing datasets eitherdo not provide pose annotations or include scene types unrelated to roboticapplications. Many datasets also lack the diversity of poses and occlusionsfound in crowded human scenes. To address this limitation we introduceJRDB-Pose, a large-scale dataset and benchmark for multi-person pose estimationand tracking using videos captured from a social navigation robot. The datasetcontains challenge scenes with crowded indoor and outdoor locations and adiverse range of scales and occlusion types. JRDB-Pose provides human poseannotations with per-keypoint occlusion labels and track IDs consistent acrossthe scene. A public evaluation server is made available for fair evaluation ona held-out test set. JRDB-Pose is available at https://jrdb.erc.monash.edu/ .
使用的是全景相机,而不是普通多视角相机
dataset multi-person pose-estimation tracking@inproceedings{JRDB-Pose, title = {JRDB-Pose: A Large-scale Dataset for Multi-Person Pose Estimation and Tracking}, author = {Vendrow, Edward and Le, Duy Tho and Rezatofighi, Hamid}, year = {2022}, tags = {dataset, multi-person, pose-estimation, tracking}, } - Bootstrapping Human Optical Flow and PoseAritro Roy Arko, James J. Little, and Kwang Moo YiIn 2022
We propose a bootstrapping framework to enhance human optical flow and pose.We show that, for videos involving humans in scenes, we can improve both theoptical flow and the pose estimation quality of humans by considering the twotasks at the same time. We enhance optical flow estimates by fine-tuning themto fit the human pose estimates and vice versa. In more detail, we optimize thepose and optical flow networks to, at inference time, agree with each other. Weshow that this results in state-of-the-art results on the Human 3.6M and 3DPoses in the Wild datasets, as well as a human-related subset of the Sinteldataset, both in terms of pose estimation accuracy and the optical flowaccuracy at human joint locations. Code available athttps://github.com/ubc-vision/bootstrapping-human-optical-flow-and-pose
使用pose来增强光流
human optical-flow pose-estimation@inproceedings{2210.15121, title = {Bootstrapping Human Optical Flow and Pose}, author = {Arko, Aritro Roy and Little, James J. and Yi, Kwang Moo}, year = {2022}, tags = {human, optical-flow, pose-estimation}, } - Self-Supervised 3D Human Pose Estimation in Static Video Via Neural RenderingLuca Schmidtke, Benjamin Hou, Athanasios Vlontzos, and Bernhard KainzIn 2022
Inferring 3D human pose from 2D images is a challenging and long-standingproblem in the field of computer vision with many applications including motioncapture, virtual reality, surveillance or gait analysis for sports andmedicine. We present preliminary results for a method to estimate 3D pose from2D video containing a single person and a static background without the needfor any manual landmark annotations. We achieve this by formulating a simpleyet effective self-supervision task: our model is required to reconstruct arandom frame of a video given a frame from another timepoint and a renderedimage of a transformed human shape template. Crucially for optimisation, ourray casting based rendering pipeline is fully differentiable, enabling end toend training solely based on the reconstruction task.
pose-estimation neural-rendering self-supervised@inproceedings{2210.04514, title = {Self-Supervised 3D Human Pose Estimation in Static Video Via Neural Rendering}, author = {Schmidtke, Luca and Hou, Benjamin and Vlontzos, Athanasios and Kainz, Bernhard}, year = {2022}, tags = {pose-estimation, neural-rendering, self-supervised}, } - AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose RegressionYabo Xiao, Xiaojuan Wang, Dongdong Yu, Kai Su, Lei Jin, Mei Song, Shuicheng Yan, and Jian ZhaoIn 2022
Multi-person pose estimation generally follows top-down and bottom-upparadigms. Both of them use an extra stage (\boldsymbole.g., humandetection in top-down paradigm or grouping process in bottom-up paradigm) tobuild the relationship between the human instance and corresponding keypoints,thus leading to the high computation cost and redundant two-stage pipeline. Toaddress the above issue, we propose to represent the human parts as adaptivepoints and introduce a fine-grained body representation method. The novel bodyrepresentation is able to sufficiently encode the diverse pose information andeffectively model the relationship between the human instance and correspondingkeypoints in a single-forward pass. With the proposed body representation, wefurther deliver a compact single-stage multi-person pose regression network,termed as AdaptivePose. During inference, our proposed network only needs asingle-step decode operation to form the multi-person pose without complexpost-processes and refinements. We employ AdaptivePose for both 2D/3Dmulti-person pose estimation tasks to verify the effectiveness of AdaptivePose.Without any bells and whistles, we achieve the most competitive performance onMS COCO and CrowdPose in terms of accuracy and speed. Furthermore, theoutstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates theeffectiveness and generalizability on 3D scenes. Code is available athttps://github.com/buptxyb666/AdaptivePose.
multi-person monocular pose-estimation@inproceedings{AdaptivePose++, title = {AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression}, author = {Xiao, Yabo and Wang, Xiaojuan and Yu, Dongdong and Su, Kai and Jin, Lei and Song, Mei and Yan, Shuicheng and Zhao, Jian}, year = {2022}, tags = {multi-person, monocular, pose-estimation}, } - SmartMocap: Joint Estimation of Human and Camera Motion using Uncalibrated RGB CamerasNitin Saini, Chun-hao P. Huang, Michael J. Black, and Aamir AhmadIn 2022
Markerless human motion capture (mocap) from multiple RGB cameras is a widelystudied problem. Existing methods either need calibrated cameras or calibratethem relative to a static camera, which acts as the reference frame for themocap system. The calibration step has to be done a priori for every capturesession, which is a tedious process, and re-calibration is required whenevercameras are intentionally or accidentally moved. In this paper, we propose amocap method which uses multiple static and moving extrinsically uncalibratedRGB cameras. The key components of our method are as follows. First, since thecameras and the subject can move freely, we select the ground plane as a commonreference to represent both the body and the camera motions unlike existingmethods which represent bodies in the camera coordinate. Second, we learn aprobability distribution of short human motion sequences (\sim1sec) relativeto the ground plane and leverage it to disambiguate between the camera andhuman motion. Third, we use this distribution as a motion prior in a novelmulti-stage optimization approach to fit the SMPL human body model and thecamera poses to the human body keypoints on the images. Finally, we show thatour method can work on a variety of datasets ranging from aerial cameras tosmartphones. It also gives more accurate results compared to thestate-of-the-art on the task of monocular human mocap with a static camera. Ourcode is available for research purposes onhttps://github.com/robot-perception-group/SmartMocap.
mocap pose-estimation uncalibrated@inproceedings{SmartMocap, title = {SmartMocap: Joint Estimation of Human and Camera Motion using Uncalibrated RGB Cameras}, author = {Saini, Nitin and Huang, Chun-hao P. and Black, Michael J. and Ahmad, Aamir}, year = {2022}, tags = {mocap, pose-estimation, uncalibrated}, } -
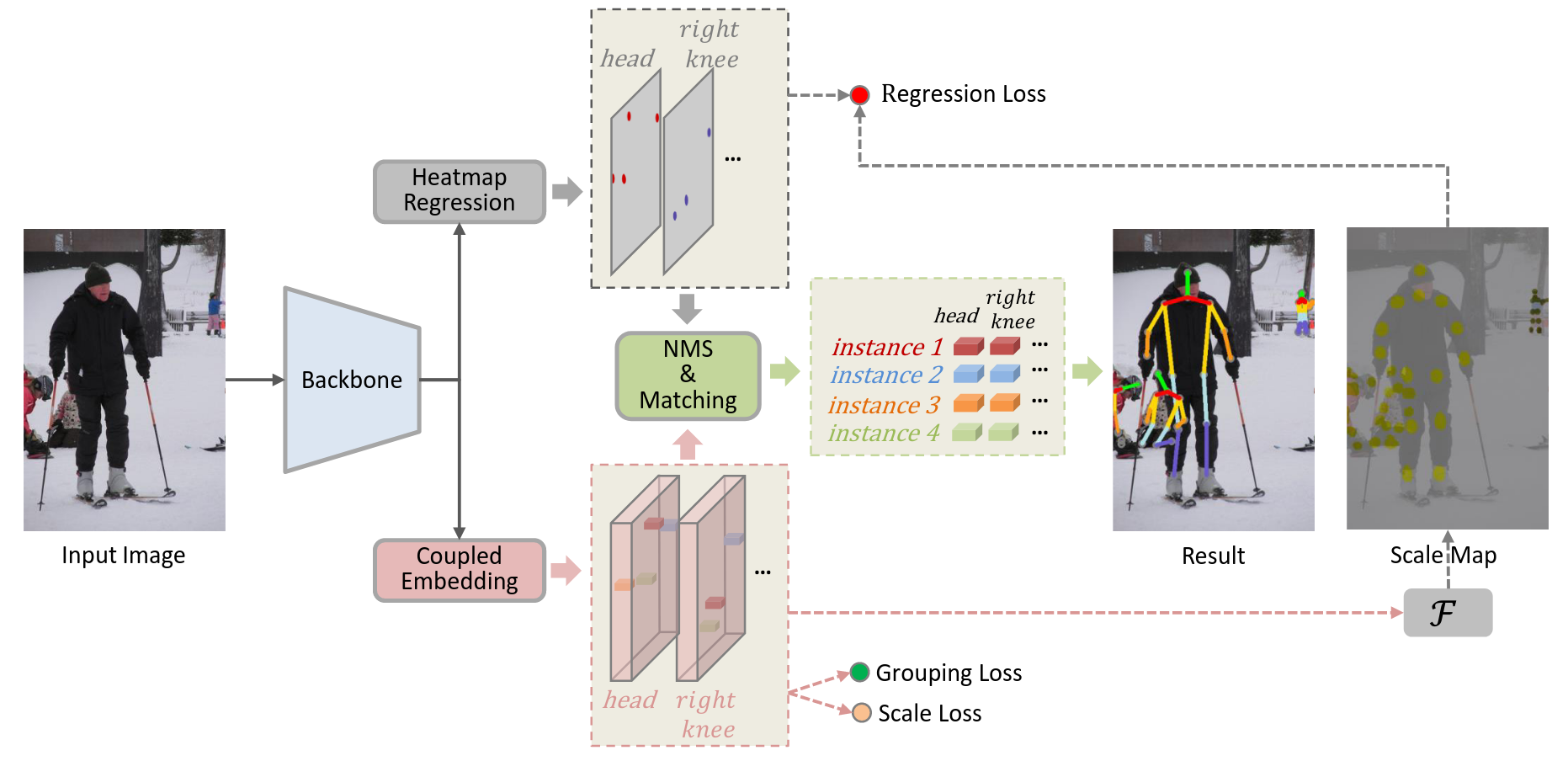 Regularizing Vector Embedding in Bottom-Up Human Pose EstimationIn ECCV 2022
Regularizing Vector Embedding in Bottom-Up Human Pose EstimationIn ECCV 2022使用scale来提升embedding
human-pose-estimation bottom-up@inproceedings{Regularizing_Vector_Embedding, title = {Regularizing Vector Embedding in Bottom-Up Human Pose Estimation}, author = {}, year = {2022}, tags = {human-pose-estimation, bottom-up}, booktitle = {ECCV}, } -
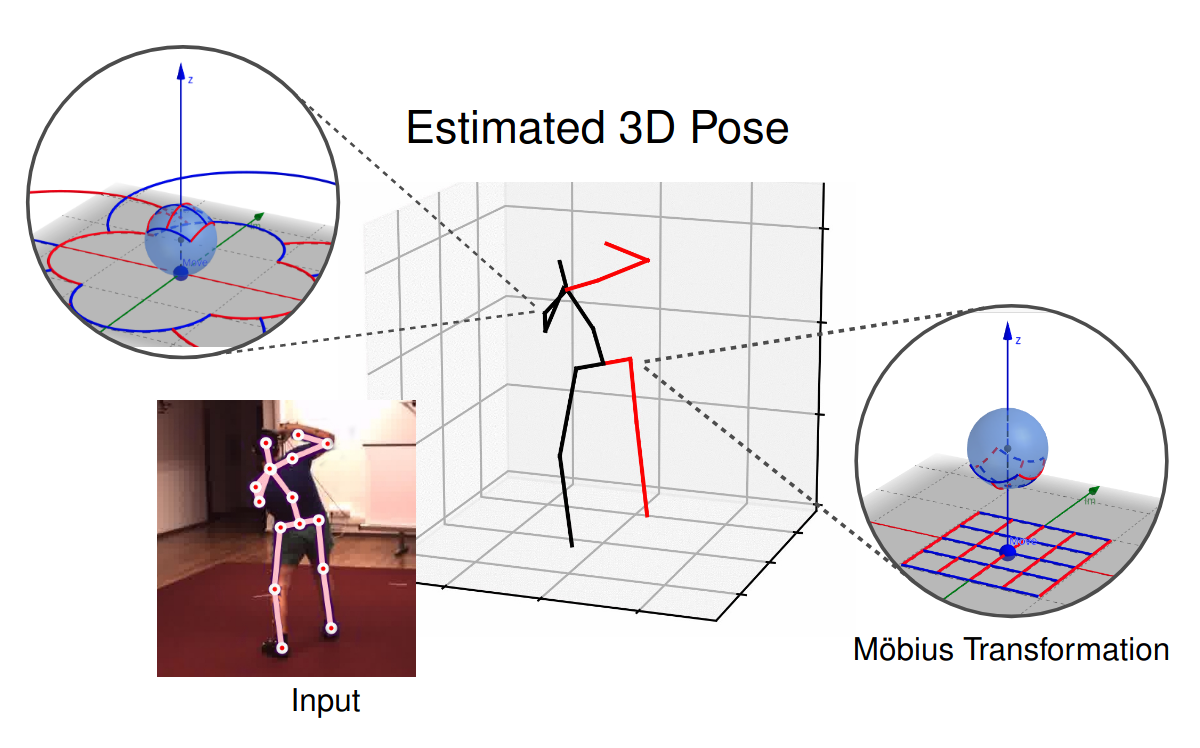 3D Human Pose Estimation Using Möbius Graph Convolutional NetworksNiloofar Azizi, Horst Possegger, Emanuele Rodolà, and Horst BischofIn ECCV 2022
3D Human Pose Estimation Using Möbius Graph Convolutional NetworksNiloofar Azizi, Horst Possegger, Emanuele Rodolà, and Horst BischofIn ECCV 20223D human pose estimation is fundamental to understanding human behavior.Recently, promising results have been achieved by graph convolutional networks(GCNs), which achieve state-of-the-art performance and provide ratherlight-weight architectures. However, a major limitation of GCNs is theirinability to encode all the transformations between joints explicitly. Toaddress this issue, we propose a novel spectral GCN using the Möbiustransformation (MöbiusGCN). In particular, this allows us to directly andexplicitly encode the transformation between joints, resulting in asignificantly more compact representation. Compared to even the lightestarchitectures so far, our novel approach requires 90-98% fewer parameters, i.e.our lightest MöbiusGCN uses only 0.042M trainable parameters. Besides thedrastic parameter reduction, explicitly encoding the transformation of jointsalso enables us to achieve state-of-the-art results. We evaluate our approachon the two challenging pose estimation benchmarks, Human3.6M and MPI-INF-3DHP,demonstrating both state-of-the-art results and the generalization capabilitiesof MöbiusGCN.
human-pose-estimation gcn@inproceedings{Mobius_GCN, title = {3D Human Pose Estimation Using Möbius Graph Convolutional Networks}, author = {Azizi, Niloofar and Possegger, Horst and Rodolà, Emanuele and Bischof, Horst}, year = {2022}, tags = {human-pose-estimation, gcn}, booktitle = {ECCV}, } -
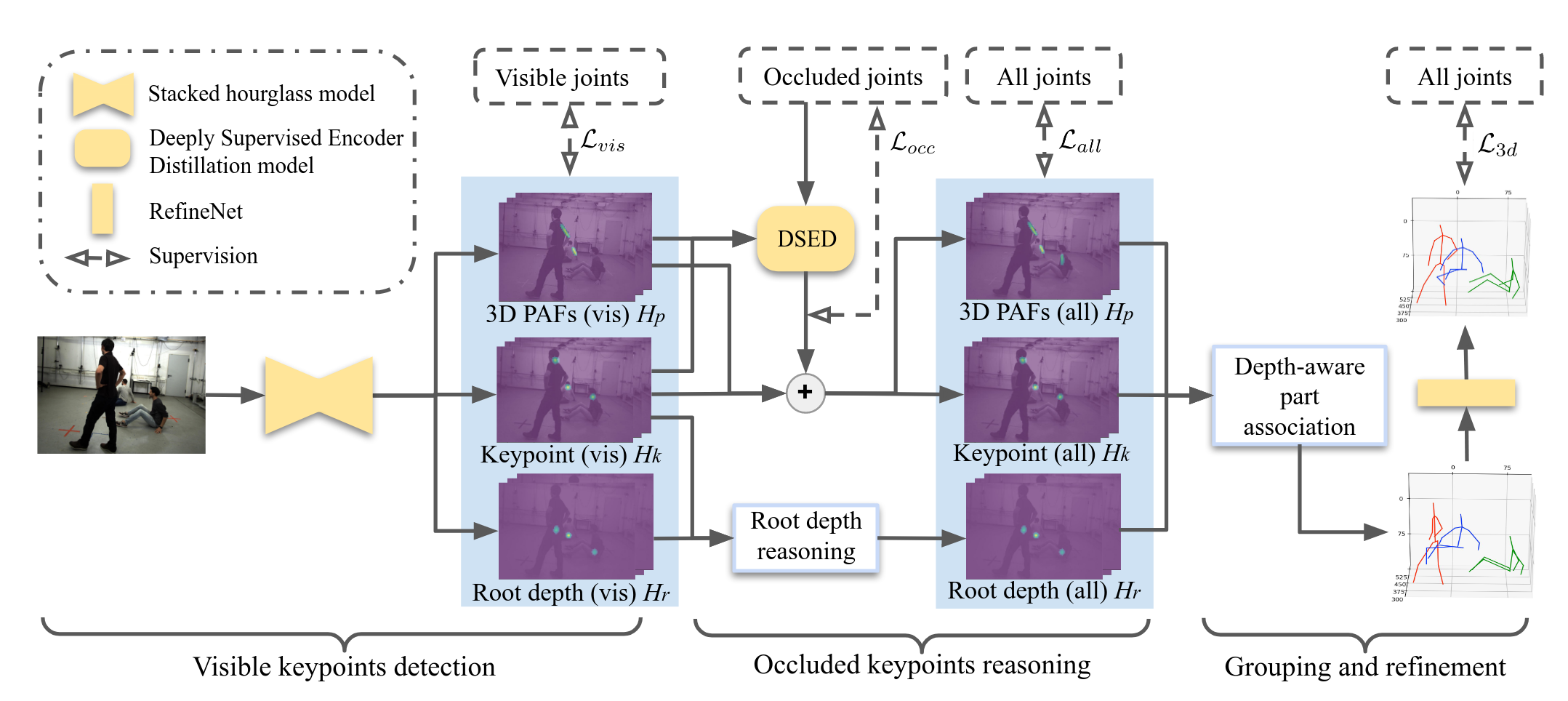 Explicit Occlusion Reasoning for Multi-person 3D Human Pose EstimationQihao Liu, Yi Zhang, Song Bai, and Alan YuilleIn ECCV 2022
Explicit Occlusion Reasoning for Multi-person 3D Human Pose EstimationQihao Liu, Yi Zhang, Song Bai, and Alan YuilleIn ECCV 2022Occlusion poses a great threat to monocular multi-person 3D human poseestimation due to large variability in terms of the shape, appearance, andposition of occluders. While existing methods try to handle occlusion with posepriors/constraints, data augmentation, or implicit reasoning, they still failto generalize to unseen poses or occlusion cases and may make large mistakeswhen multiple people are present. Inspired by the remarkable ability of humansto infer occluded joints from visible cues, we develop a method to explicitlymodel this process that significantly improves bottom-up multi-person humanpose estimation with or without occlusions. First, we split the task into twosubtasks: visible keypoints detection and occluded keypoints reasoning, andpropose a Deeply Supervised Encoder Distillation (DSED) network to solve thesecond one. To train our model, we propose a Skeleton-guided human ShapeFitting (SSF) approach to generate pseudo occlusion labels on the existingdatasets, enabling explicit occlusion reasoning. Experiments show thatexplicitly learning from occlusions improves human pose estimation. Inaddition, exploiting feature-level information of visible joints allows us toreason about occluded joints more accurately. Our method outperforms both thestate-of-the-art top-down and bottom-up methods on several benchmarks.
估计被遮挡住的数据然后再进行association
human-pose-estimation 1vmp@inproceedings{Occulusion_reasoning, title = {Explicit Occlusion Reasoning for Multi-person 3D Human Pose Estimation}, author = {Liu, Qihao and Zhang, Yi and Bai, Song and Yuille, Alan}, year = {2022}, tags = {human-pose-estimation, 1vmp}, booktitle = {ECCV}, }
2021
-
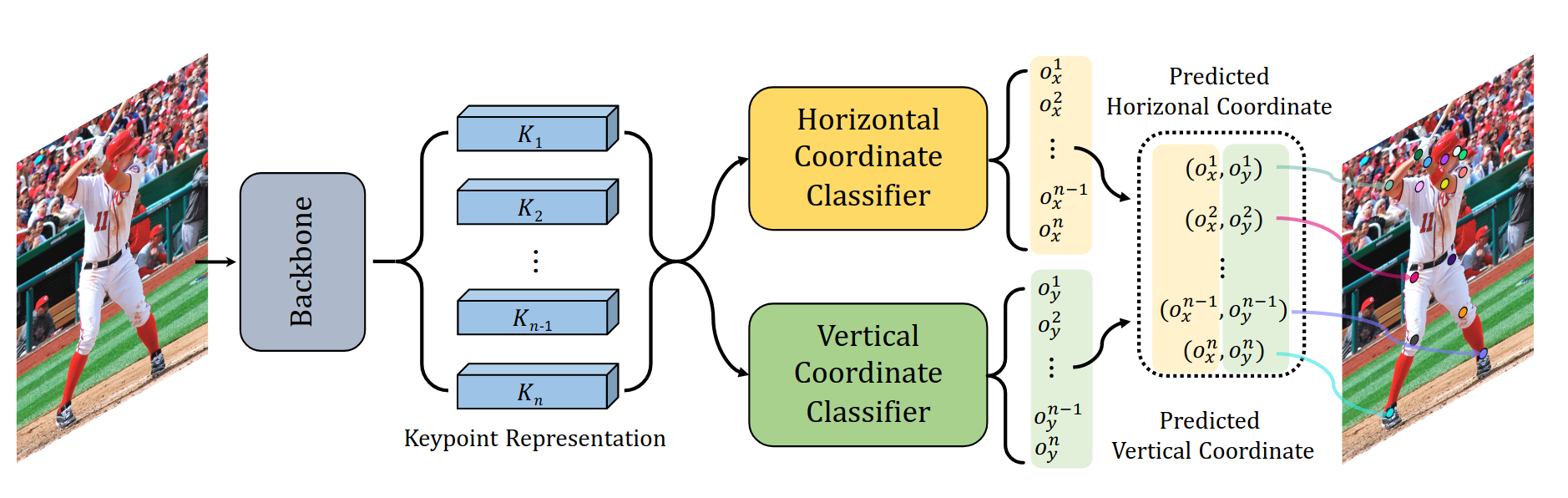 SimCC: a Simple Coordinate Classification Perspective for Human Pose EstimationYanjie Li, Sen Yang, Peidong Liu, Shoukui Zhang, Yunxiao Wang, Zhicheng Wang, Wankou Yang, and Shu-Tao XiaIn ECCV 2021
SimCC: a Simple Coordinate Classification Perspective for Human Pose EstimationYanjie Li, Sen Yang, Peidong Liu, Shoukui Zhang, Yunxiao Wang, Zhicheng Wang, Wankou Yang, and Shu-Tao XiaIn ECCV 2021The 2D heatmap-based approaches have dominated Human Pose Estimation (HPE)for years due to high performance. However, the long-standing quantizationerror problem in the 2D heatmap-based methods leads to several well-knowndrawbacks: 1) The performance for the low-resolution inputs is limited; 2) Toimprove the feature map resolution for higher localization precision, multiplecostly upsampling layers are required; 3) Extra post-processing is adopted toreduce the quantization error. To address these issues, we aim to explore abrand new scheme, called \textitSimCC, which reformulates HPE as twoclassification tasks for horizontal and vertical coordinates. The proposedSimCC uniformly divides each pixel into several bins, thus achieving\emphsub-pixel localization precision and low quantization error. Benefitingfrom that, SimCC can omit additional refinement post-processing and excludeupsampling layers under certain settings, resulting in a more simple andeffective pipeline for HPE. Extensive experiments conducted over COCO,CrowdPose, and MPII datasets show that SimCC outperforms heatmap-basedcounterparts, especially in low-resolution settings by a large margin.
从坐标分类的角度来看2D人体姿态估计问题
human-pose-estimation@inproceedings{SimCC, title = {SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation}, author = {Li, Yanjie and Yang, Sen and Liu, Peidong and Zhang, Shoukui and Wang, Yunxiao and Wang, Zhicheng and Yang, Wankou and Xia, Shu-Tao}, year = {2021}, tags = {human-pose-estimation}, booktitle = {ECCV}, }