3dpose
Papers with tag 3dpose
2022
- On Triangulation as a Form of Self-Supervision for 3D Human Pose EstimationSoumava Kumar Roy, Leonardo Citraro, Sina Honari, and Pascal FuaIn 2022
Supervised approaches to 3D pose estimation from single images are remarkablyeffective when labeled data is abundant. However, as the acquisition ofground-truth 3D labels is labor intensive and time consuming, recent attentionhas shifted towards semi- and weakly-supervised learning. Generating aneffective form of supervision with little annotations still poses majorchallenge in crowded scenes. In this paper we propose to impose multi-viewgeometrical constraints by means of a weighted differentiable triangulation anduse it as a form of self-supervision when no labels are available. We thereforetrain a 2D pose estimator in such a way that its predictions correspond to there-projection of the triangulated 3D pose and train an auxiliary network onthem to produce the final 3D poses. We complement the triangulation with aweighting mechanism that alleviates the impact of noisy predictions caused byself-occlusion or occlusion from other subjects. We demonstrate theeffectiveness of our semi-supervised approach on Human3.6M and MPI-INF-3DHPdatasets, as well as on a new multi-view multi-person dataset that featuresocclusion.
使用多视角三角化来自监督
human mv 1p 3dpose e2e self-supervised@inproceedings{2203.15865, title = {On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation}, author = {Roy, Soumava Kumar and Citraro, Leonardo and Honari, Sina and Fua, Pascal}, year = {2022}, tags = {human, mv, 1p, 3dpose, e2e, self-supervised}, } -
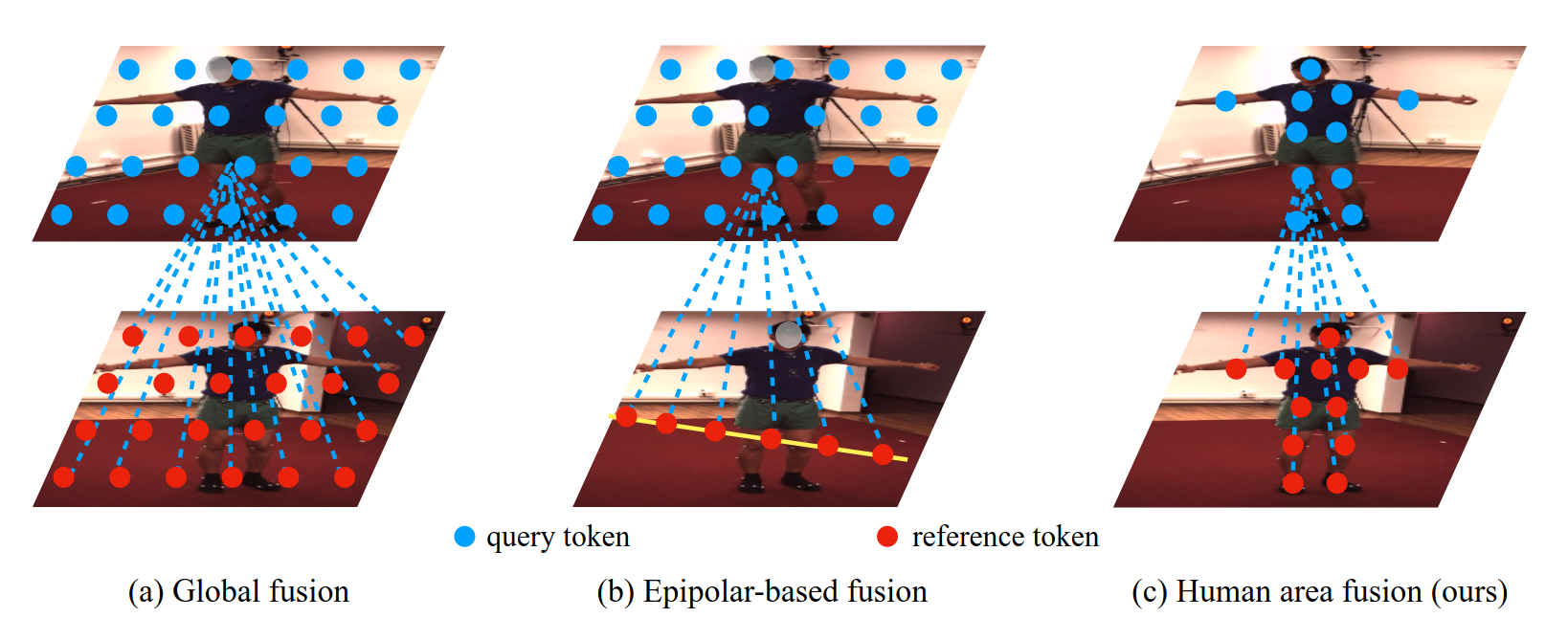 PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimationHaoyu Ma, Zhe Wang, Yifei Chen, Deying Kong, Liangjian Chen, Xingwei Liu, Xiangyi Yan, Hao Tang, and Xiaohui XieIn 2022
PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimationHaoyu Ma, Zhe Wang, Yifei Chen, Deying Kong, Liangjian Chen, Xingwei Liu, Xiangyi Yan, Hao Tang, and Xiaohui XieIn 2022Recently, the vision transformer and its variants have played an increasinglyimportant role in both monocular and multi-view human pose estimation.Considering image patches as tokens, transformers can model the globaldependencies within the entire image or across images from other views.However, global attention is computationally expensive. As a consequence, it isdifficult to scale up these transformer-based methods to high-resolutionfeatures and many views. In this paper, we propose the token-Pruned Pose Transformer (PPT) for 2Dhuman pose estimation, which can locate a rough human mask and performsself-attention only within selected tokens. Furthermore, we extend our PPT tomulti-view human pose estimation. Built upon PPT, we propose a new cross-viewfusion strategy, called human area fusion, which considers all human foregroundpixels as corresponding candidates. Experimental results on COCO and MPIIdemonstrate that our PPT can match the accuracy of previous pose transformermethods while reducing the computation. Moreover, experiments on Human 3.6M andSki-Pose demonstrate that our Multi-view PPT can efficiently fuse cues frommultiple views and achieve new state-of-the-art results.
使用人体区域来做fusion
human mv 1p 3dpose@inproceedings{PPT, title = {PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimation}, author = {Ma, Haoyu and Wang, Zhe and Chen, Yifei and Kong, Deying and Chen, Liangjian and Liu, Xingwei and Yan, Xiangyi and Tang, Hao and Xie, Xiaohui}, year = {2022}, tags = {human, mv, 1p, 3dpose}, } - VTP: Volumetric Transformer for Multi-view Multi-person 3D Pose EstimationYuxing Chen, Renshu Gu, Ouhan Huang, and Gangyong JiaIn 2022
This paper presents Volumetric Transformer Pose estimator (VTP), the first 3Dvolumetric transformer framework for multi-view multi-person 3D human poseestimation. VTP aggregates features from 2D keypoints in all camera views anddirectly learns the spatial relationships in the 3D voxel space in anend-to-end fashion. The aggregated 3D features are passed through 3Dconvolutions before being flattened into sequential embeddings and fed into atransformer. A residual structure is designed to further improve theperformance. In addition, the sparse Sinkhorn attention is empowered to reducethe memory cost, which is a major bottleneck for volumetric representations,while also achieving excellent performance. The output of the transformer isagain concatenated with 3D convolutional features by a residual design. Theproposed VTP framework integrates the high performance of the transformer withvolumetric representations, which can be used as a good alternative to theconvolutional backbones. Experiments on the Shelf, Campus and CMU Panopticbenchmarks show promising results in terms of both Mean Per Joint PositionError (MPJPE) and Percentage of Correctly estimated Parts (PCP). Our code willbe available.
使用3DVolTransformer回归人体坐标
human mv mp 3dpose transformer@inproceedings{VTP, title = {VTP: Volumetric Transformer for Multi-view Multi-person 3D Pose Estimation}, author = {Chen, Yuxing and Gu, Renshu and Huang, Ouhan and Jia, Gangyong}, year = {2022}, tags = {human, mv, mp, 3dpose, transformer}, } - PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimationHaoyu Ma, Zhe Wang, Yifei Chen, Deying Kong, Liangjian Chen, Xingwei Liu, Xiangyi Yan, Hao Tang, and Xiaohui XieIn 2022
Recently, the vision transformer and its variants have played an increasinglyimportant role in both monocular and multi-view human pose estimation.Considering image patches as tokens, transformers can model the globaldependencies within the entire image or across images from other views.However, global attention is computationally expensive. As a consequence, it isdifficult to scale up these transformer-based methods to high-resolutionfeatures and many views. In this paper, we propose the token-Pruned Pose Transformer (PPT) for 2Dhuman pose estimation, which can locate a rough human mask and performsself-attention only within selected tokens. Furthermore, we extend our PPT tomulti-view human pose estimation. Built upon PPT, we propose a new cross-viewfusion strategy, called human area fusion, which considers all human foregroundpixels as corresponding candidates. Experimental results on COCO and MPIIdemonstrate that our PPT can match the accuracy of previous pose transformermethods while reducing the computation. Moreover, experiments on Human 3.6M andSki-Pose demonstrate that our Multi-view PPT can efficiently fuse cues frommultiple views and achieve new state-of-the-art results.
使用人体区域来做fusion
human mv 1p 3dpose@inproceedings{PPU, title = {PPT: token-Pruned Pose Transformer for monocular and multi-view human pose estimation}, author = {Ma, Haoyu and Wang, Zhe and Chen, Yifei and Kong, Deying and Chen, Liangjian and Liu, Xingwei and Yan, Xiangyi and Tang, Hao and Xie, Xiaohui}, year = {2022}, tags = {human, mv, 1p, 3dpose}, }
2021
- Learning Temporal 3D Human Pose Estimation with Pseudo-LabelsArij Bouazizi, Ulrich Kressel, and Vasileios BelagiannisIn 2021
We present a simple, yet effective, approach for self-supervised 3D humanpose estimation. Unlike the prior work, we explore the temporal informationnext to the multi-view self-supervision. During training, we rely ontriangulating 2D body pose estimates of a multiple-view camera system. Atemporal convolutional neural network is trained with the generated 3Dground-truth and the geometric multi-view consistency loss, imposinggeometrical constraints on the predicted 3D body skeleton. During inference,our model receives a sequence of 2D body pose estimates from a single-view topredict the 3D body pose for each of them. An extensive evaluation shows thatour method achieves state-of-the-art performance in the Human3.6M andMPI-INF-3DHP benchmarks. Our code and models are publicly available at\urlhttps://github.com/vru2020/TM_HPE/.
输入一段序列的2D关键点,输出3Dpose,通过多视角的一致性来监督
human monocular 1p 3dpose self-supervised@inproceedings{temporal3d, title = {Learning Temporal 3D Human Pose Estimation with Pseudo-Labels}, author = {Bouazizi, Arij and Kressel, Ulrich and Belagiannis, Vasileios}, year = {2021}, tags = {human, monocular, 1p, 3dpose, self-supervised}, } - Direct Multi-view Multi-person 3D Pose EstimationTao Wang, Jianfeng Zhang, Yujun Cai, Shuicheng Yan, and Jiashi FengIn 2021
We present Multi-view Pose transformer (MvP) for estimating multi-person 3Dposes from multi-view images. Instead of estimating 3D joint locations fromcostly volumetric representation or reconstructing the per-person 3D pose frommultiple detected 2D poses as in previous methods, MvP directly regresses themulti-person 3D poses in a clean and efficient way, without relying onintermediate tasks. Specifically, MvP represents skeleton joints as learnablequery embeddings and let them progressively attend to and reason over themulti-view information from the input images to directly regress the actual 3Djoint locations. To improve the accuracy of such a simple pipeline, MvPpresents a hierarchical scheme to concisely represent query embeddings ofmulti-person skeleton joints and introduces an input-dependent query adaptationapproach. Further, MvP designs a novel geometrically guided attentionmechanism, called projective attention, to more precisely fuse the cross-viewinformation for each joint. MvP also introduces a RayConv operation tointegrate the view-dependent camera geometry into the feature representationsfor augmenting the projective attention. We show experimentally that our MvPmodel outperforms the state-of-the-art methods on several benchmarks whilebeing much more efficient. Notably, it achieves 92.3% AP25 on the challengingPanoptic dataset, improving upon the previous best approach [36] by 9.8%. MvPis general and also extendable to recovering human mesh represented by the SMPLmodel, thus useful for modeling multi-person body shapes. Code and models areavailable at https://github.com/sail-sg/mvp.
多视角的feature直接通过transformer聚合
human mv mp 3dpose transformer@inproceedings{DMVMP, title = {Direct Multi-view Multi-person 3D Pose Estimation}, author = {Wang, Tao and Zhang, Jianfeng and Cai, Yujun and Yan, Shuicheng and Feng, Jiashi}, year = {2021}, tags = {human, mv, mp, 3dpose, transformer}, } - Generalizable Human Pose TriangulationKristijan Bartol, David Bojanić, Tomislav Petković, and Tomislav PribanićIn 2021
We address the problem of generalizability for multi-view 3D human poseestimation. The standard approach is to first detect 2D keypoints in images andthen apply triangulation from multiple views. Even though the existing methodsachieve remarkably accurate 3D pose estimation on public benchmarks, most ofthem are limited to a single spatial camera arrangement and their number.Several methods address this limitation but demonstrate significantly degradedperformance on novel views. We propose a stochastic framework for human posetriangulation and demonstrate a superior generalization across different cameraarrangements on two public datasets. In addition, we apply the same approach tothe fundamental matrix estimation problem, showing that the proposed method cansuccessfully apply to other computer vision problems. The stochastic frameworkachieves more than 8.8% improvement on the 3D pose estimation task, compared tothe state-of-the-art, and more than 30% improvement for fundamental matrixestimation, compared to a standard algorithm.
提出了一个框架来解决泛化的三角化问题
human mv 1p 3dpose@inproceedings{GeneralTri, title = {Generalizable Human Pose Triangulation}, author = {Bartol, Kristijan and Bojanić, David and Petković, Tomislav and Pribanić, Tomislav}, year = {2021}, tags = {human, mv, 1p, 3dpose}, } - Adaptive Multi-view and Temporal Fusing Transformer for 3D Human Pose EstimationHui Shuai, Lele Wu, and Qingshan LiuIn 2021
This paper proposes a unified framework dubbed Multi-view and Temporal FusingTransformer (MTF-Transformer) to adaptively handle varying view numbers andvideo length without camera calibration in 3D Human Pose Estimation (HPE). Itconsists of Feature Extractor, Multi-view Fusing Transformer (MFT), andTemporal Fusing Transformer (TFT). Feature Extractor estimates 2D pose fromeach image and fuses the prediction according to the confidence. It providespose-focused feature embedding and makes subsequent modules computationallylightweight. MFT fuses the features of a varying number of views with a novelRelative-Attention block. It adaptively measures the implicit relativerelationship between each pair of views and reconstructs more informativefeatures. TFT aggregates the features of the whole sequence and predicts 3Dpose via a transformer. It adaptively deals with the video of arbitrary lengthand fully unitizes the temporal information. The migration of transformersenables our model to learn spatial geometry better and preserve robustness forvarying application scenarios. We report quantitative and qualitative resultson the Human3.6M, TotalCapture, and KTH Multiview Football II. Compared withstate-of-the-art methods with camera parameters, MTF-Transformer obtainscompetitive results and generalizes well to dynamic capture with an arbitrarynumber of unseen views.
多视角特征融合的transformer以及时序融合的transformer
human mv 1p 3dpose transformer@inproceedings{2110.05092, title = {Adaptive Multi-view and Temporal Fusing Transformer for 3D Human Pose Estimation}, author = {Shuai, Hui and Wu, Lele and Liu, Qingshan}, year = {2021}, tags = {human, mv, 1p, 3dpose, transformer}, } - Graph-Based 3D Multi-Person Pose Estimation Using Multi-View ImagesSize Wu, Sheng Jin, Wentao Liu, Lei Bai, Chen Qian, Dong Liu, and Wanli OuyangIn 2021
This paper studies the task of estimating the 3D human poses of multiplepersons from multiple calibrated camera views. Following the top-down paradigm,we decompose the task into two stages, i.e. person localization and poseestimation. Both stages are processed in coarse-to-fine manners. And we proposethree task-specific graph neural networks for effective message passing. For 3Dperson localization, we first use Multi-view Matching Graph Module (MMG) tolearn the cross-view association and recover coarse human proposals. The CenterRefinement Graph Module (CRG) further refines the results via flexiblepoint-based prediction. For 3D pose estimation, the Pose Regression GraphModule (PRG) learns both the multi-view geometry and structural relationsbetween human joints. Our approach achieves state-of-the-art performance on CMUPanoptic and Shelf datasets with significantly lower computation complexity.
通过图网络来学习多人对应关系
human mv mp 3dpose GNN@inproceedings{graphmp, title = {Graph-Based 3D Multi-Person Pose Estimation Using Multi-View Images}, author = {Wu, Size and Jin, Sheng and Liu, Wentao and Bai, Lei and Qian, Chen and Liu, Dong and Ouyang, Wanli}, year = {2021}, tags = {human, mv, mp, 3dpose, GNN}, } - FLEX: Extrinsic Parameters-free Multi-view 3D Human Motion ReconstructionBrian Gordon, Sigal Raab, Guy Azov, Raja Giryes, and Daniel Cohen-OrIn ECCV 2021
The increasing availability of video recordings made by multiple cameras hasoffered new means for mitigating occlusion and depth ambiguities in pose andmotion reconstruction methods. Yet, multi-view algorithms strongly depend oncamera parameters; particularly, the relative transformations between thecameras. Such a dependency becomes a hurdle once shifting to dynamic capture inuncontrolled settings. We introduce FLEX (Free muLti-view rEconstruXion), anend-to-end extrinsic parameter-free multi-view model. FLEX is extrinsicparameter-free (dubbed ep-free) in the sense that it does not require extrinsiccamera parameters. Our key idea is that the 3D angles between skeletal parts,as well as bone lengths, are invariant to the camera position. Hence, learning3D rotations and bone lengths rather than locations allows predicting commonvalues for all camera views. Our network takes multiple video streams, learnsfused deep features through a novel multi-view fusion layer, and reconstructs asingle consistent skeleton with temporally coherent joint rotations. Wedemonstrate quantitative and qualitative results on three public datasets, andon synthetic multi-person video streams captured by dynamic cameras. We compareour model to state-of-the-art methods that are not ep-free and show that in theabsence of camera parameters, we outperform them by a large margin whileobtaining comparable results when camera parameters are available. Code,trained models, and other materials are available on our project page.
输入多视角的序列的2D估计,估计脚步接触标签以及骨长、3D旋转,可以不给定相机
3dpose mv1p@inproceedings{FLEX, title = {FLEX: Extrinsic Parameters-free Multi-view 3D Human Motion Reconstruction}, author = {Gordon, Brian and Raab, Sigal and Azov, Guy and Giryes, Raja and Cohen-Or, Daniel}, year = {2021}, tags = {3dpose, mv1p}, booktitle = {ECCV}, }
2020
- AdaFuse: Adaptive Multiview Fusion for Accurate Human Pose Estimation in the WildZhe Zhang, Chunyu Wang, Weichao Qiu, Wenhu Qin, and Wenjun ZengIn 2020
Occlusion is probably the biggest challenge for human pose estimation in thewild. Typical solutions often rely on intrusive sensors such as IMUs to detectoccluded joints. To make the task truly unconstrained, we present AdaFuse, anadaptive multiview fusion method, which can enhance the features in occludedviews by leveraging those in visible views. The core of AdaFuse is to determinethe point-point correspondence between two views which we solve effectively byexploring the sparsity of the heatmap representation. We also learn an adaptivefusion weight for each camera view to reflect its feature quality in order toreduce the chance that good features are undesirably corrupted by “bad”views. The fusion model is trained end-to-end with the pose estimation network,and can be directly applied to new camera configurations without additionaladaptation. We extensively evaluate the approach on three public datasetsincluding Human3.6M, Total Capture and CMU Panoptic. It outperforms thestate-of-the-arts on all of them. We also create a large scale syntheticdataset Occlusion-Person, which allows us to perform numerical evaluation onthe occluded joints, as it provides occlusion labels for every joint in theimages. The dataset and code are released athttps://github.com/zhezh/adafuse-3d-human-pose.
同时输入多视角的图像关键点估计heatmap,输出2D关键点
human mv 1p 3dpose@inproceedings{AdaFuse, title = {AdaFuse: Adaptive Multiview Fusion for Accurate Human Pose Estimation in the Wild}, author = {Zhang, Zhe and Wang, Chunyu and Qiu, Weichao and Qin, Wenhu and Zeng, Wenjun}, year = {2020}, tags = {human, mv, 1p, 3dpose}, }
2019
- Learnable Triangulation of Human PoseKarim Iskakov, Egor Burkov, Victor Lempitsky, and Yury MalkovIn 2019
We present two novel solutions for multi-view 3D human pose estimation basedon new learnable triangulation methods that combine 3D information frommultiple 2D views. The first (baseline) solution is a basic differentiablealgebraic triangulation with an addition of confidence weights estimated fromthe input images. The second solution is based on a novel method of volumetricaggregation from intermediate 2D backbone feature maps. The aggregated volumeis then refined via 3D convolutions that produce final 3D joint heatmaps andallow modelling a human pose prior. Crucially, both approaches are end-to-enddifferentiable, which allows us to directly optimize the target metric. Wedemonstrate transferability of the solutions across datasets and considerablyimprove the multi-view state of the art on the Human3.6M dataset. Videodemonstration, annotations and additional materials will be posted on ourproject page (https://saic-violet.github.io/learnable-triangulation).
多个视角的特征反投影到3D空间中通过3D网络获得最终输出
human mv 1p 3dpose e2e@inproceedings{lrtri, title = {Learnable Triangulation of Human Pose}, author = {Iskakov, Karim and Burkov, Egor and Lempitsky, Victor and Malkov, Yury}, year = {2019}, tags = {human, mv, 1p, 3dpose, e2e}, } - Cross View Fusion for 3D Human Pose EstimationHaibo Qiu, Chunyu Wang, Jingdong Wang, Naiyan Wang, and Wenjun ZengIn 2019
We present an approach to recover absolute 3D human poses from multi-viewimages by incorporating multi-view geometric priors in our model. It consistsof two separate steps: (1) estimating the 2D poses in multi-view images and (2)recovering the 3D poses from the multi-view 2D poses. First, we introduce across-view fusion scheme into CNN to jointly estimate 2D poses for multipleviews. Consequently, the 2D pose estimation for each view already benefits fromother views. Second, we present a recursive Pictorial Structure Model torecover the 3D pose from the multi-view 2D poses. It gradually improves theaccuracy of 3D pose with affordable computational cost. We test our method ontwo public datasets H36M and Total Capture. The Mean Per Joint Position Errorson the two datasets are 26mm and 29mm, which outperforms the state-of-the-artsremarkably (26mm vs 52mm, 29mm vs 35mm). Our code is released at\urlhttps://github.com/microsoft/multiview-human-pose-estimation-pytorch.
直接多视角的融合
human mv 1p 3dpose@inproceedings{crossviewfusion, title = {Cross View Fusion for 3D Human Pose Estimation}, author = {Qiu, Haibo and Wang, Chunyu and Wang, Jingdong and Wang, Naiyan and Zeng, Wenjun}, year = {2019}, tags = {human, mv, 1p, 3dpose}, }
2018
- Self-supervised Multi-view Person Association and Its ApplicationsMinh Vo, Ersin Yumer, Kalyan Sunkavalli, Sunil Hadap, Yaser Sheikh, and Srinivasa NarasimhanIn 2018
Reliable markerless motion tracking of people participating in a complexgroup activity from multiple moving cameras is challenging due to frequentocclusions, strong viewpoint and appearance variations, and asynchronous videostreams. To solve this problem, reliable association of the same person acrossdistant viewpoints and temporal instances is essential. We present aself-supervised framework to adapt a generic person appearance descriptor tothe unlabeled videos by exploiting motion tracking, mutual exclusionconstraints, and multi-view geometry. The adapted discriminative descriptor isused in a tracking-by-clustering formulation. We validate the effectiveness ofour descriptor learning on WILDTRACK [14] and three new complex social scenescaptured by multiple cameras with up to 60 people "in the wild". We reportsignificant improvement in association accuracy (up to 18%) and stable andcoherent 3D human skeleton tracking (5 to 10 times) over the baseline. Usingthe reconstructed 3D skeletons, we cut the input videos into a multi-anglevideo where the image of a specified person is shown from the best visiblefront-facing camera. Our algorithm detects inter-human occlusion to determinethe camera switching moment while still maintaining the flow of the actionwell.
自监督的特征学习进行人体的聚类
human mv mp 3dpose self-supervised@inproceedings{MVPAssociation, title = {Self-supervised Multi-view Person Association and Its Applications}, author = {Vo, Minh and Yumer, Ersin and Sunkavalli, Kalyan and Hadap, Sunil and Sheikh, Yaser and Narasimhan, Srinivasa}, year = {2018}, tags = {human, mv, mp, 3dpose, self-supervised}, }
2017
- Harvesting Multiple Views for Marker-less 3D Human Pose AnnotationsGeorgios Pavlakos, Xiaowei Zhou, Konstantinos G. Derpanis, and Kostas DaniilidisIn 2017
Recent advances with Convolutional Networks (ConvNets) have shifted thebottleneck for many computer vision tasks to annotated data collection. In thispaper, we present a geometry-driven approach to automatically collectannotations for human pose prediction tasks. Starting from a generic ConvNetfor 2D human pose, and assuming a multi-view setup, we describe an automaticway to collect accurate 3D human pose annotations. We capitalize on constraintsoffered by the 3D geometry of the camera setup and the 3D structure of thehuman body to probabilistically combine per view 2D ConvNet predictions into aglobally optimal 3D pose. This 3D pose is used as the basis for harvestingannotations. The benefit of the annotations produced automatically with ourapproach is demonstrated in two challenging settings: (i) fine-tuning a genericConvNet-based 2D pose predictor to capture the discriminative aspects of asubject’s appearance (i.e.,"personalization"), and (ii) training a ConvNet fromscratch for single view 3D human pose prediction without leveraging 3D posegroundtruth. The proposed multi-view pose estimator achieves state-of-the-artresults on standard benchmarks, demonstrating the effectiveness of our methodin exploiting the available multi-view information.
多视角的heatmap生成了3D特征,然后使用3Dpictorial获取骨架位置
human mv 1p 3dpose@inproceedings{harvesting, title = {Harvesting Multiple Views for Marker-less 3D Human Pose Annotations}, author = {Pavlakos, Georgios and Zhou, Xiaowei and Derpanis, Konstantinos G. and Daniilidis, Kostas}, year = {2017}, tags = {human, mv, 1p, 3dpose}, }