view-synthesis
Papers with tag view-synthesis
2022
- HDHumans: A Hybrid Approach for High-fidelity Digital HumansMarc Habermann, Lingjie Liu, Weipeng Xu, Gerard Pons-Moll, Michael Zollhoefer, and Christian TheobaltIn 2022
Photo-real digital human avatars are of enormous importance in graphics, asthey enable immersive communication over the globe, improve gaming andentertainment experiences, and can be particularly beneficial for AR and VRsettings. However, current avatar generation approaches either fall short inhigh-fidelity novel view synthesis, generalization to novel motions,reproduction of loose clothing, or they cannot render characters at the highresolution offered by modern displays. To this end, we propose HDHumans, whichis the first method for HD human character synthesis that jointly produces anaccurate and temporally coherent 3D deforming surface and highlyphoto-realistic images of arbitrary novel views and of motions not seen attraining time. At the technical core, our method tightly integrates a classicaldeforming character template with neural radiance fields (NeRF). Our method iscarefully designed to achieve a synergy between classical surface deformationand NeRF. First, the template guides the NeRF, which allows synthesizing novelviews of a highly dynamic and articulated character and even enables thesynthesis of novel motions. Second, we also leverage the dense pointcloudsresulting from NeRF to further improve the deforming surface via 3D-to-3Dsupervision. We outperform the state of the art quantitatively andqualitatively in terms of synthesis quality and resolution, as well as thequality of 3D surface reconstruction.
DeepCap的拓展
human-synthesis view-synthesis human-modeling human-performance-capture@inproceedings{HDHumans, title = {HDHumans: A Hybrid Approach for High-fidelity Digital Humans}, author = {Habermann, Marc and Liu, Lingjie and Xu, Weipeng and Pons-Moll, Gerard and Zollhoefer, Michael and Theobalt, Christian}, year = {2022}, tags = {human-synthesis, view-synthesis, human-modeling, human-performance-capture}, } -
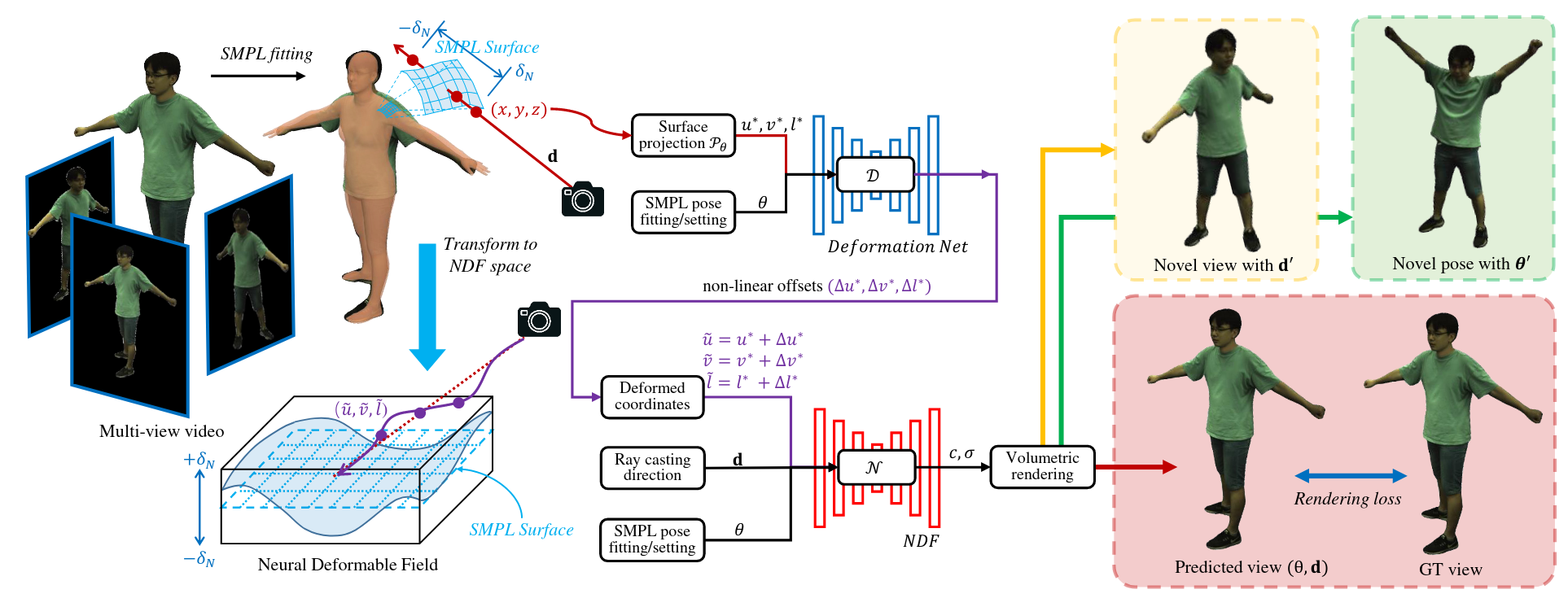 NDF: Neural Deformable Fields for Dynamic Human ModellingRuiqi Zhang, and Jie ChenIn ECCV 2022
NDF: Neural Deformable Fields for Dynamic Human ModellingRuiqi Zhang, and Jie ChenIn ECCV 2022We propose Neural Deformable Fields (NDF), a new representation for dynamichuman digitization from a multi-view video. Recent works proposed to representa dynamic human body with shared canonical neural radiance fields which linksto the observation space with deformation fields estimations. However, thelearned canonical representation is static and the current design of thedeformation fields is not able to represent large movements or detailedgeometry changes. In this paper, we propose to learn a neural deformable fieldwrapped around a fitted parametric body model to represent the dynamic human.The NDF is spatially aligned by the underlying reference surface. A neuralnetwork is then learned to map pose to the dynamics of NDF. The proposed NDFrepresentation can synthesize the digitized performer with novel views andnovel poses with a detailed and reasonable dynamic appearance. Experiments showthat our method significantly outperforms recent human synthesis methods.
view-synthesis@inproceedings{NDF, title = {NDF: Neural Deformable Fields for Dynamic Human Modelling}, author = {Zhang, Ruiqi and Chen, Jie}, year = {2022}, tags = {view-synthesis}, booktitle = {ECCV}, }
- Boosting Point Clouds Rendering via Radiance MappingXiaoyang Huang, Yi Zhang, Bingbing Ni, Teng Li, Kai Chen, and Wenjun ZhangIn 2022
Recent years we have witnessed rapid development in NeRF-based imagerendering due to its high quality. However, point clouds rendering is somehowless explored. Compared to NeRF-based rendering which suffers from densespatial sampling, point clouds rendering is naturally less computationintensive, which enables its deployment in mobile computing device. In thiswork, we focus on boosting the image quality of point clouds rendering with acompact model design. We first analyze the adaption of the volume renderingformulation on point clouds. Based on the analysis, we simplify the NeRFrepresentation to a spatial mapping function which only requires singleevaluation per pixel. Further, motivated by ray marching, we rectify the thenoisy raw point clouds to the estimated intersection between rays and surfacesas queried coordinates, which could avoid spatial frequency collapse andneighbor point disturbance. Composed of rasterization, spatial mapping and therefinement stages, our method achieves the state-of-the-art performance onpoint clouds rendering, outperforming prior works by notable margins, with asmaller model size. We obtain a PSNR of 31.74 on NeRF-Synthetic, 25.88 onScanNet and 30.81 on DTU. Code and data would be released soon.
基于point cloud做rendering, 实现每条ray一次evaluation.
view-synthesis point-cloud@inproceedings{boosting_pc_render, title = {Boosting Point Clouds Rendering via Radiance Mapping}, author = {Huang, Xiaoyang and Zhang, Yi and Ni, Bingbing and Li, Teng and Chen, Kai and Zhang, Wenjun}, year = {2022}, tags = {view-synthesis, point-cloud}, sida = {基于point cloud做rendering, 实现每条ray一次evaluation.}, } - VIINTER: View Interpolation with Implicit Neural Representations of ImagesBrandon Yushan Feng, Susmija Jabbireddy, and Amitabh VarshneyIn 2022
We present VIINTER, a method for view interpolation by interpolating theimplicit neural representation (INR) of the captured images. We leverage thelearned code vector associated with each image and interpolate between thesecodes to achieve viewpoint transitions. We propose several techniques thatsignificantly enhance the interpolation quality. VIINTER signifies a new way toachieve view interpolation without constructing 3D structure, estimating cameraposes, or computing pixel correspondence. We validate the effectiveness ofVIINTER on several multi-view scenes with different types of camera layout andscene composition. As the development of INR of images (as opposed to surfaceor volume) has centered around tasks like image fitting and super-resolution,with VIINTER, we show its capability for view interpolation and offer apromising outlook on using INR for image manipulation tasks.
用INR和latent vectors记录多张图片, 通过插值latent vectors实现view interpolation.
view-synthesis@inproceedings{VIINTER, title = {VIINTER: View Interpolation with Implicit Neural Representations of Images}, author = {Feng, Brandon Yushan and Jabbireddy, Susmija and Varshney, Amitabh}, year = {2022}, tags = {view-synthesis}, sida = {用INR和latent vectors记录多张图片, 通过插值latent vectors实现view interpolation.}, } -
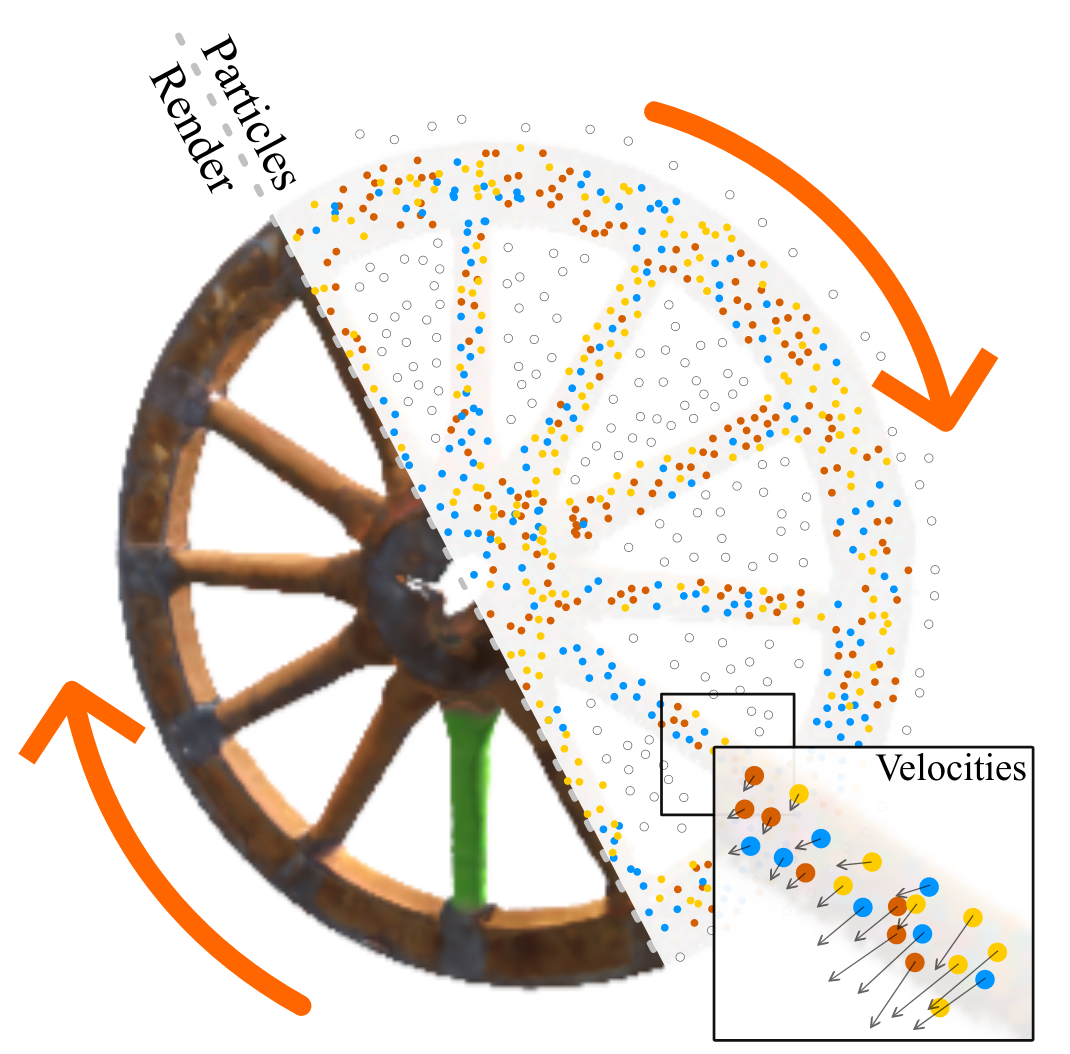 ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic ScenesJad Abou-Chakra, Feras Dayoub, and Niko SünderhaufIn 2022
ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic ScenesJad Abou-Chakra, Feras Dayoub, and Niko SünderhaufIn 2022Neural Radiance Fields (NeRFs) learn implicit representations of - typicallystatic - environments from images. Our paper extends NeRFs to handle dynamicscenes in an online fashion. We propose ParticleNeRF that adapts to changes inthe geometry of the environment as they occur, learning a new up-to-daterepresentation every 350 ms. ParticleNeRF can represent the current state ofdynamic environments with much higher fidelity as other NeRF frameworks. Toachieve this, we introduce a new particle-based parametric encoding, whichallows the intermediate NeRF features - now coupled to particles in space - tomove with the dynamic geometry. This is possible by backpropagating thephotometric reconstruction loss into the position of the particles. Theposition gradients are interpreted as particle velocities and integrated intopositions using a position-based dynamics (PBS) physics system. Introducing PBSinto the NeRF formulation allows us to add collision constraints to theparticle motion and creates future opportunities to add other movement priorsinto the system, such as rigid and deformable body
提出了particle-based parametric encoding, 将features anchor在dynamic geometry, 实现view synthesis of dynamic scenes. 用position-based dynamics physics system表示dynamic geometry.
view-synthesis dynamic-scene@inproceedings{ParticleNeRF, title = {ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic Scenes}, author = {Abou-Chakra, Jad and Dayoub, Feras and Sünderhauf, Niko}, year = {2022}, tags = {view-synthesis, dynamic-scene}, sida = {提出了particle-based parametric encoding, 将features anchor在dynamic geometry, 实现view synthesis of dynamic scenes. 用position-based dynamics physics system表示dynamic geometry.}, } -
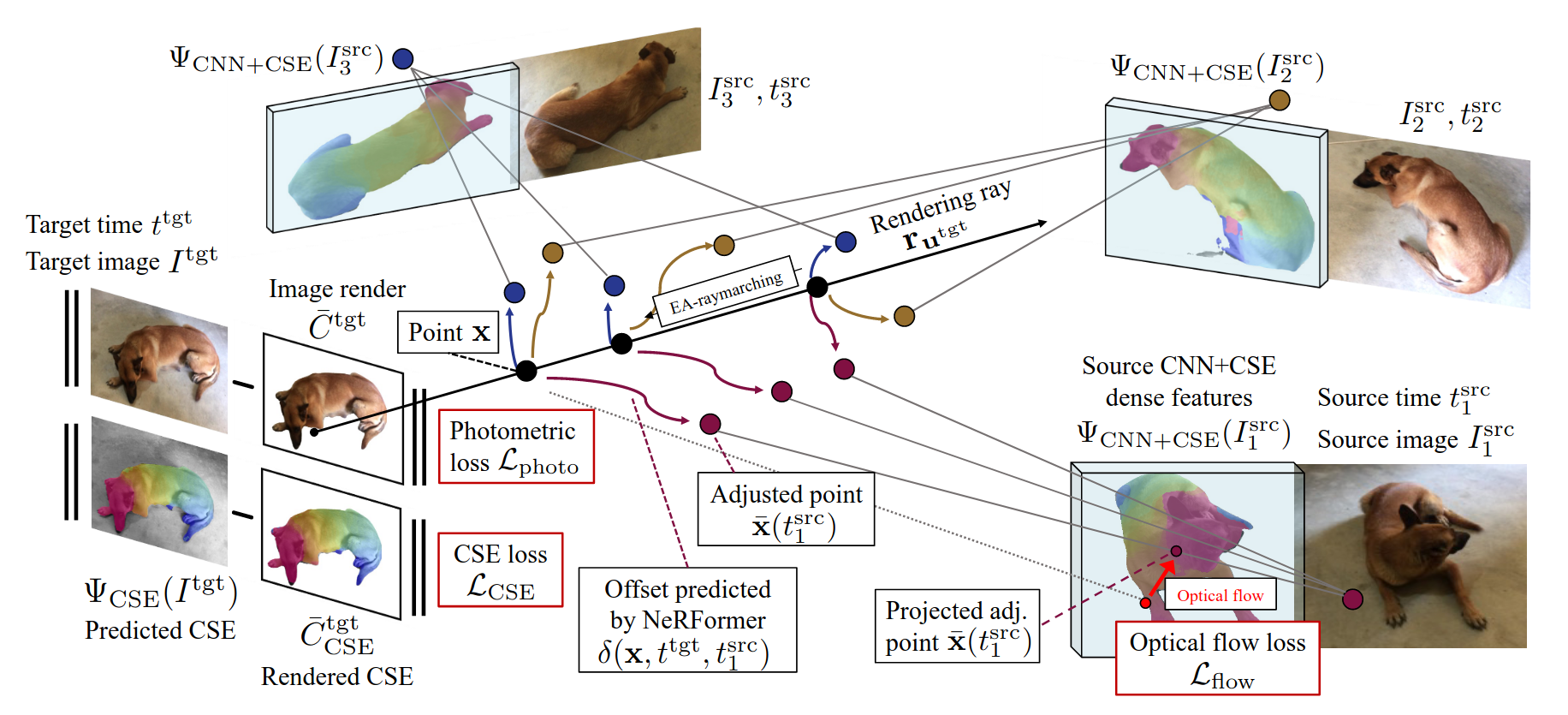 Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesSamarth Sinha, Roman Shapovalov, Jeremy Reizenstein, Ignacio Rocco, Natalia Neverova, Andrea Vedaldi, and David NovotnyIn 2022
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesSamarth Sinha, Roman Shapovalov, Jeremy Reizenstein, Ignacio Rocco, Natalia Neverova, Andrea Vedaldi, and David NovotnyIn 2022Obtaining photorealistic reconstructions of objects from sparse views isinherently ambiguous and can only be achieved by learning suitablereconstruction priors. Earlier works on sparse rigid object reconstructionsuccessfully learned such priors from large datasets such as CO3D. In thispaper, we extend this approach to dynamic objects. We use cats and dogs as arepresentative example and introduce Common Pets in 3D (CoP3D), a collection ofcrowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of thefirst large-scale datasets for benchmarking non-rigid 3D reconstruction "in thewild". We also propose Tracker-NeRF, a method for learning 4D reconstructionfrom our dataset. At test time, given a small number of video frames of anunseen object, Tracker-NeRF predicts the trajectories of its 3D points andgenerates new views, interpolating viewpoint and time. Results on CoP3D revealsignificantly better non-rigid new-view synthesis performance than existingbaselines.
提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.
monocular-video deformable-objects view-synthesis@inproceedings{Common_Pets, title = {Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories}, author = {Sinha, Samarth and Shapovalov, Roman and Reizenstein, Jeremy and Rocco, Ignacio and Neverova, Natalia and Vedaldi, Andrea and Novotny, David}, year = {2022}, tags = {monocular-video, deformable-objects, view-synthesis}, sida = {提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.}, }
2021
-
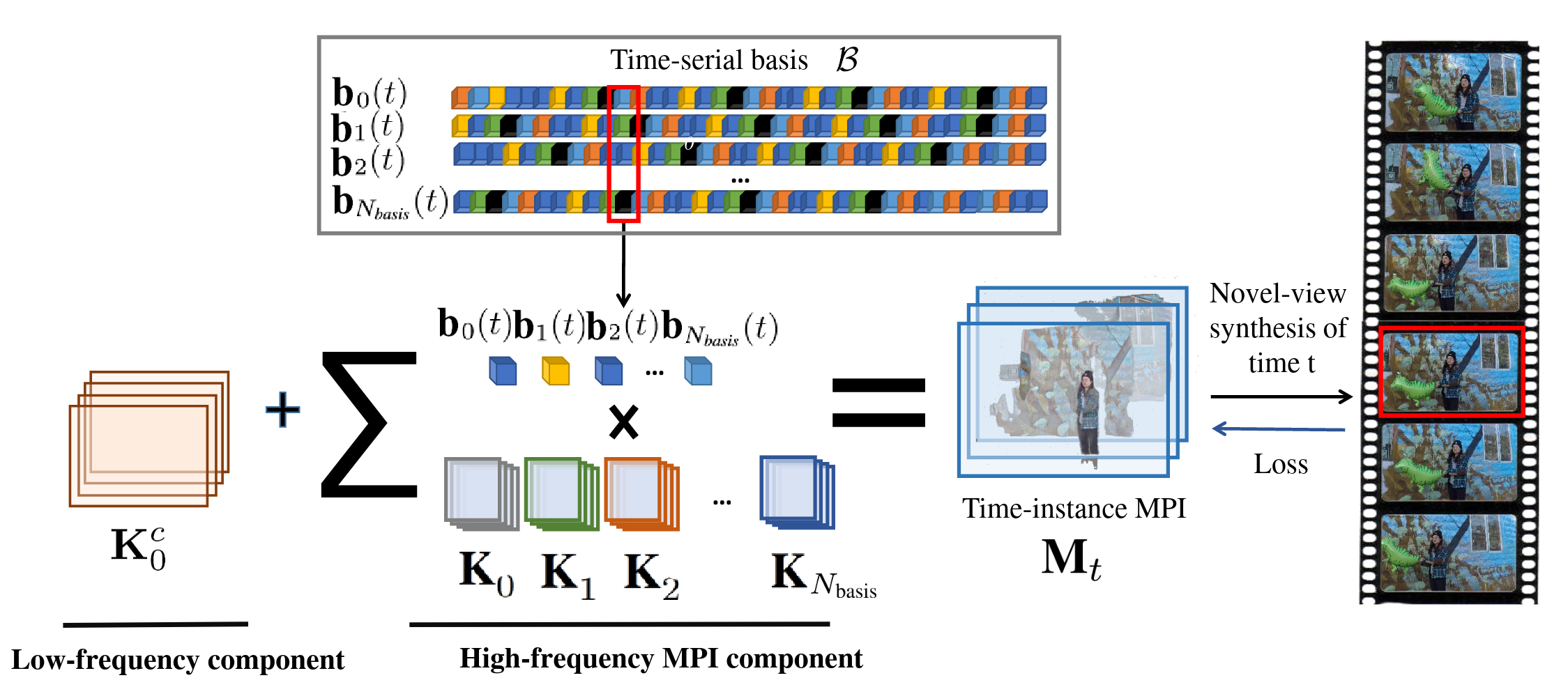 Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis LearningWenpeng Xing, and Jie ChenIn 2021
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis LearningWenpeng Xing, and Jie ChenIn 2021Novel view synthesis of static scenes has achieved remarkable advancements inproducing photo-realistic results. However, key challenges remain for immersiverendering of dynamic scenes. One of the seminal image-based rendering method,the multi-plane image (MPI), produces high novel-view synthesis quality forstatic scenes. But modelling dynamic contents by MPI is not studied. In thispaper, we propose a novel Temporal-MPI representation which is able to encodethe rich 3D and dynamic variation information throughout the entire video ascompact temporal basis and coefficients jointly learned. Time-instance MPI forrendering can be generated efficiently using mini-seconds by linearcombinations of temporal basis and coefficients from Temporal-MPI. Thusnovel-views at arbitrary time-instance will be able to be rendered viaTemporal-MPI in real-time with high visual quality. Our method is trained andevaluated on Nvidia Dynamic Scene Dataset. We show that our proposed Temporal-MPI is much faster and more compact compared with other state-of-the-artdynamic scene modelling methods.
构建一组MPI basis和coefficients, 通过linear combinations得到每一帧的MPI, 实现dynamic view synthesis.
view-synthesis dynamic-scene@inproceedings{Temporal-MPI, title = {Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning}, author = {Xing, Wenpeng and Chen, Jie}, year = {2021}, tags = {view-synthesis, dynamic-scene}, sida = {构建一组MPI basis和coefficients, 通过linear combinations得到每一帧的MPI, 实现dynamic view synthesis.}, }