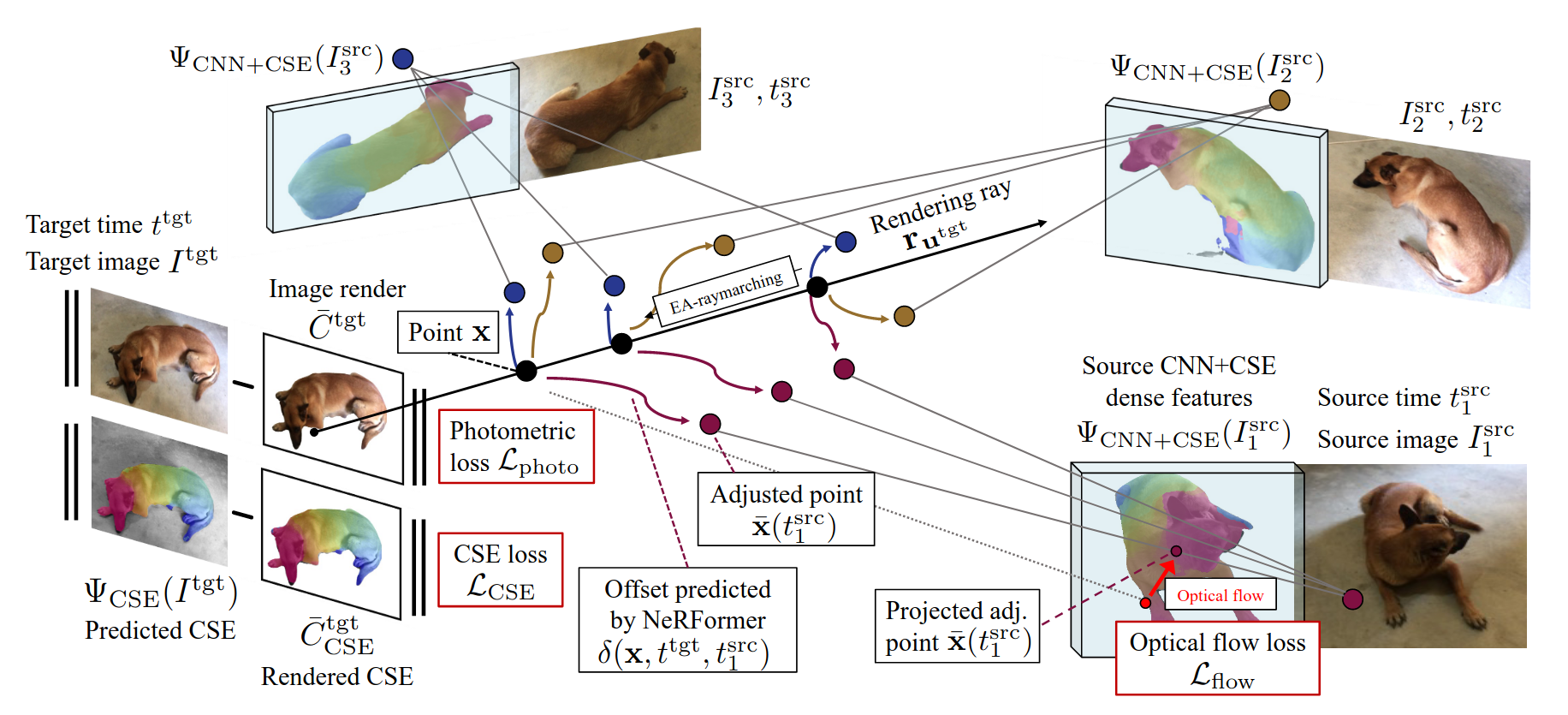
Obtaining photorealistic reconstructions of objects from sparse views isinherently ambiguous and can only be achieved by learning suitablereconstruction priors. Earlier works on sparse rigid object reconstructionsuccessfully learned such priors from large datasets such as CO3D. In thispaper, we extend this approach to dynamic objects. We use cats and dogs as arepresentative example and introduce Common Pets in 3D (CoP3D), a collection ofcrowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of thefirst large-scale datasets for benchmarking non-rigid 3D reconstruction "in thewild". We also propose Tracker-NeRF, a method for learning 4D reconstructionfrom our dataset. At test time, given a small number of video frames of anunseen object, Tracker-NeRF predicts the trajectories of its 3D points andgenerates new views, interpolating viewpoint and time. Results on CoP3D revealsignificantly better non-rigid new-view synthesis performance than existingbaselines.
@inproceedings{Common_Pets,title={Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories},author={Sinha, Samarth and Shapovalov, Roman and Reizenstein, Jeremy and Rocco, Ignacio and Neverova, Natalia and Vedaldi, Andrea and Novotny, David},year={2022},tags={monocular-video, deformable-objects, view-synthesis},sida={提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.},}
 Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesIn 2022monocular-video deformable-objects view-synthesis
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesIn 2022monocular-video deformable-objects view-synthesis