gcn
Papers with tag gcn
2022
-
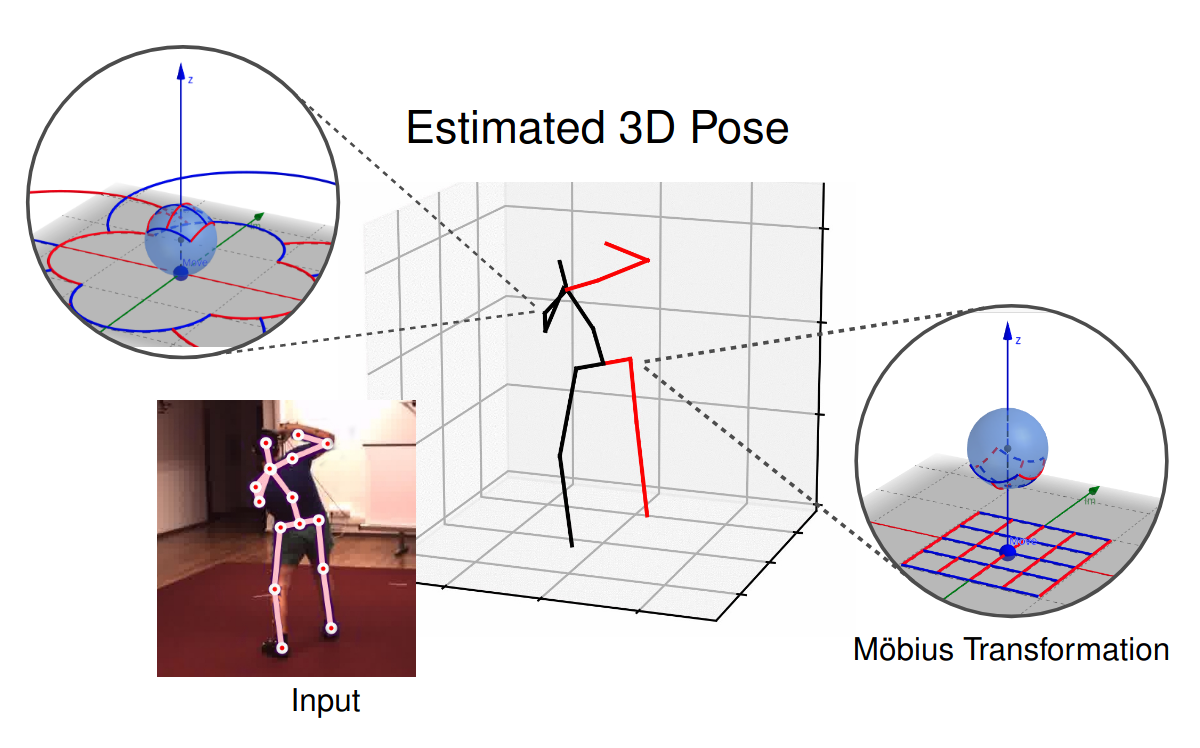 3D Human Pose Estimation Using Möbius Graph Convolutional NetworksNiloofar Azizi, Horst Possegger, Emanuele Rodolà, and Horst BischofIn ECCV 2022
3D Human Pose Estimation Using Möbius Graph Convolutional NetworksNiloofar Azizi, Horst Possegger, Emanuele Rodolà, and Horst BischofIn ECCV 20223D human pose estimation is fundamental to understanding human behavior.Recently, promising results have been achieved by graph convolutional networks(GCNs), which achieve state-of-the-art performance and provide ratherlight-weight architectures. However, a major limitation of GCNs is theirinability to encode all the transformations between joints explicitly. Toaddress this issue, we propose a novel spectral GCN using the Möbiustransformation (MöbiusGCN). In particular, this allows us to directly andexplicitly encode the transformation between joints, resulting in asignificantly more compact representation. Compared to even the lightestarchitectures so far, our novel approach requires 90-98% fewer parameters, i.e.our lightest MöbiusGCN uses only 0.042M trainable parameters. Besides thedrastic parameter reduction, explicitly encoding the transformation of jointsalso enables us to achieve state-of-the-art results. We evaluate our approachon the two challenging pose estimation benchmarks, Human3.6M and MPI-INF-3DHP,demonstrating both state-of-the-art results and the generalization capabilitiesof MöbiusGCN.
human-pose-estimation gcn@inproceedings{Mobius_GCN, title = {3D Human Pose Estimation Using Möbius Graph Convolutional Networks}, author = {Azizi, Niloofar and Possegger, Horst and Rodolà, Emanuele and Bischof, Horst}, year = {2022}, tags = {human-pose-estimation, gcn}, booktitle = {ECCV}, }