human-pose-estimation
Papers with tag human-pose-estimation
2022
-
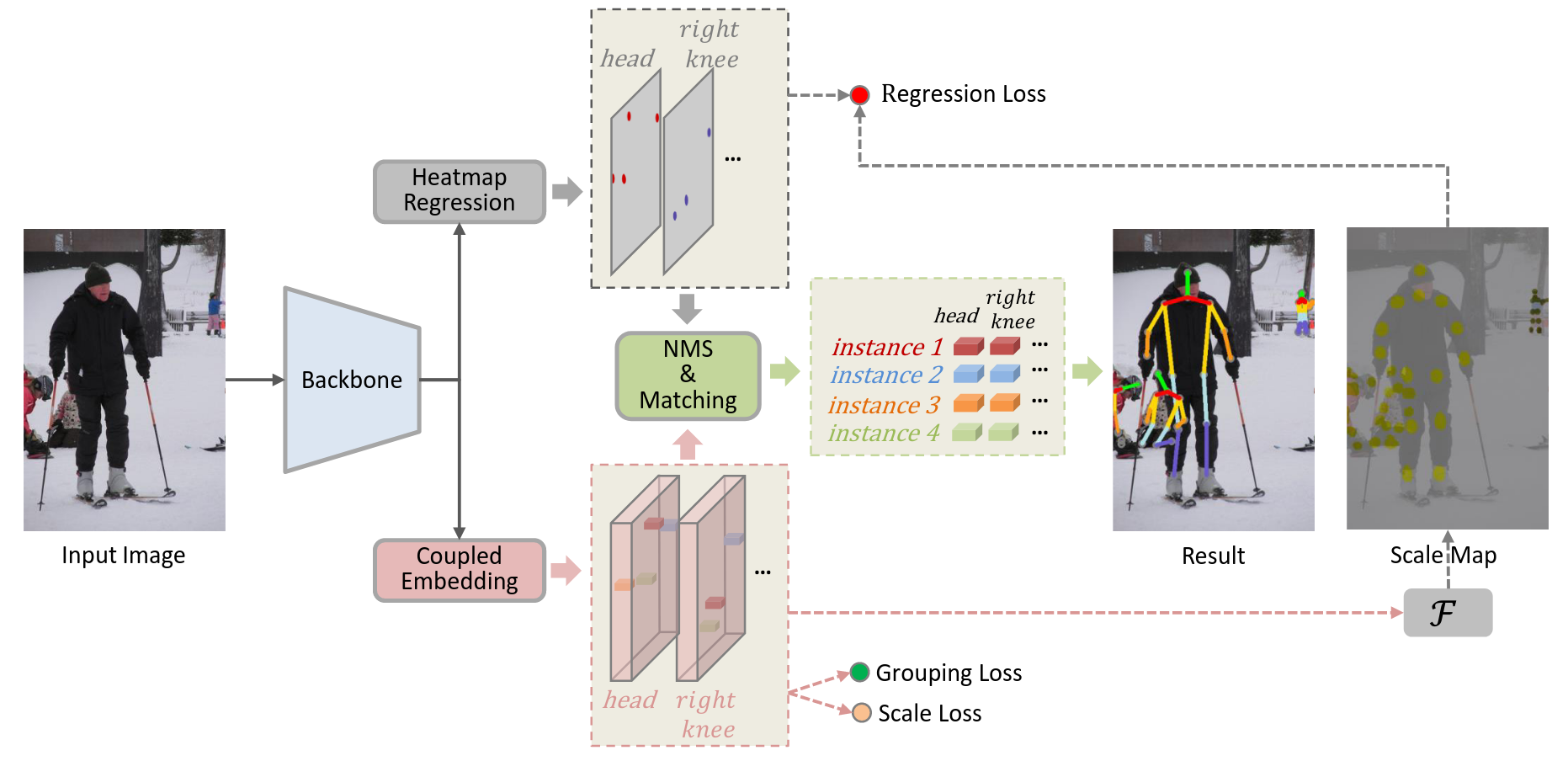 Regularizing Vector Embedding in Bottom-Up Human Pose EstimationIn ECCV 2022
Regularizing Vector Embedding in Bottom-Up Human Pose EstimationIn ECCV 2022使用scale来提升embedding
human-pose-estimation bottom-up@inproceedings{Regularizing_Vector_Embedding, title = {Regularizing Vector Embedding in Bottom-Up Human Pose Estimation}, author = {}, year = {2022}, tags = {human-pose-estimation, bottom-up}, booktitle = {ECCV}, } -
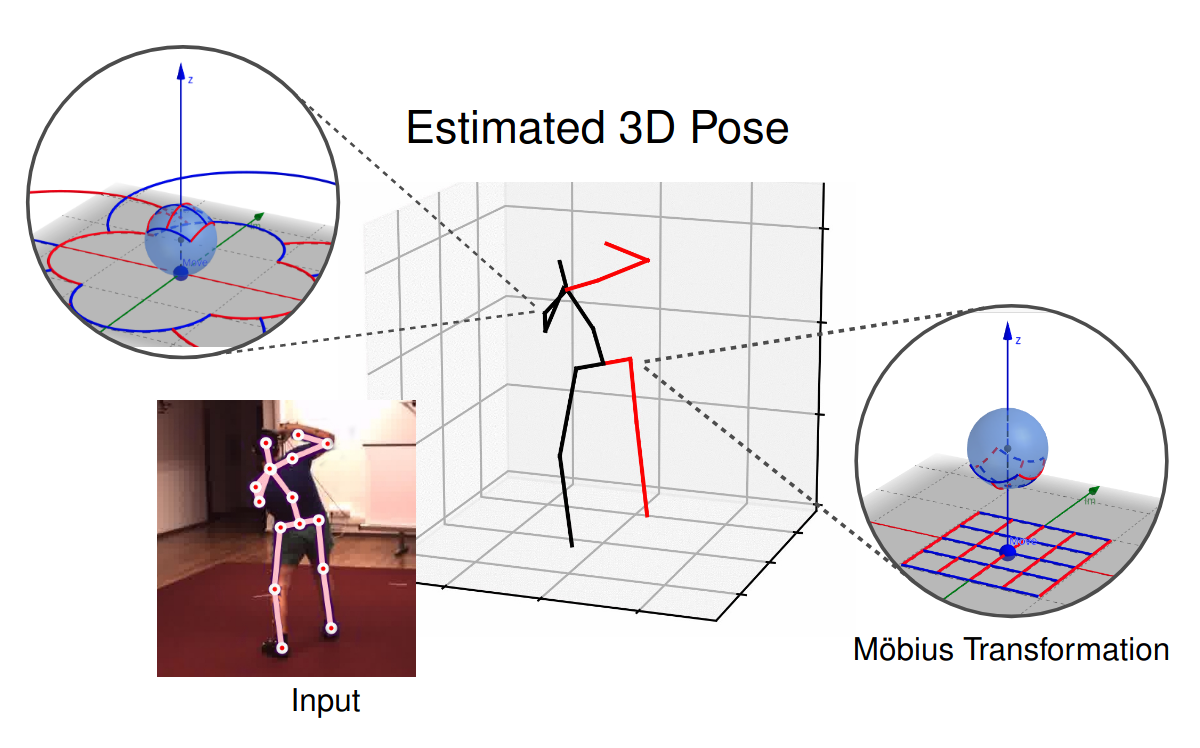 3D Human Pose Estimation Using Möbius Graph Convolutional NetworksNiloofar Azizi, Horst Possegger, Emanuele Rodolà, and Horst BischofIn ECCV 2022
3D Human Pose Estimation Using Möbius Graph Convolutional NetworksNiloofar Azizi, Horst Possegger, Emanuele Rodolà, and Horst BischofIn ECCV 20223D human pose estimation is fundamental to understanding human behavior.Recently, promising results have been achieved by graph convolutional networks(GCNs), which achieve state-of-the-art performance and provide ratherlight-weight architectures. However, a major limitation of GCNs is theirinability to encode all the transformations between joints explicitly. Toaddress this issue, we propose a novel spectral GCN using the Möbiustransformation (MöbiusGCN). In particular, this allows us to directly andexplicitly encode the transformation between joints, resulting in asignificantly more compact representation. Compared to even the lightestarchitectures so far, our novel approach requires 90-98% fewer parameters, i.e.our lightest MöbiusGCN uses only 0.042M trainable parameters. Besides thedrastic parameter reduction, explicitly encoding the transformation of jointsalso enables us to achieve state-of-the-art results. We evaluate our approachon the two challenging pose estimation benchmarks, Human3.6M and MPI-INF-3DHP,demonstrating both state-of-the-art results and the generalization capabilitiesof MöbiusGCN.
human-pose-estimation gcn@inproceedings{Mobius_GCN, title = {3D Human Pose Estimation Using Möbius Graph Convolutional Networks}, author = {Azizi, Niloofar and Possegger, Horst and Rodolà, Emanuele and Bischof, Horst}, year = {2022}, tags = {human-pose-estimation, gcn}, booktitle = {ECCV}, } -
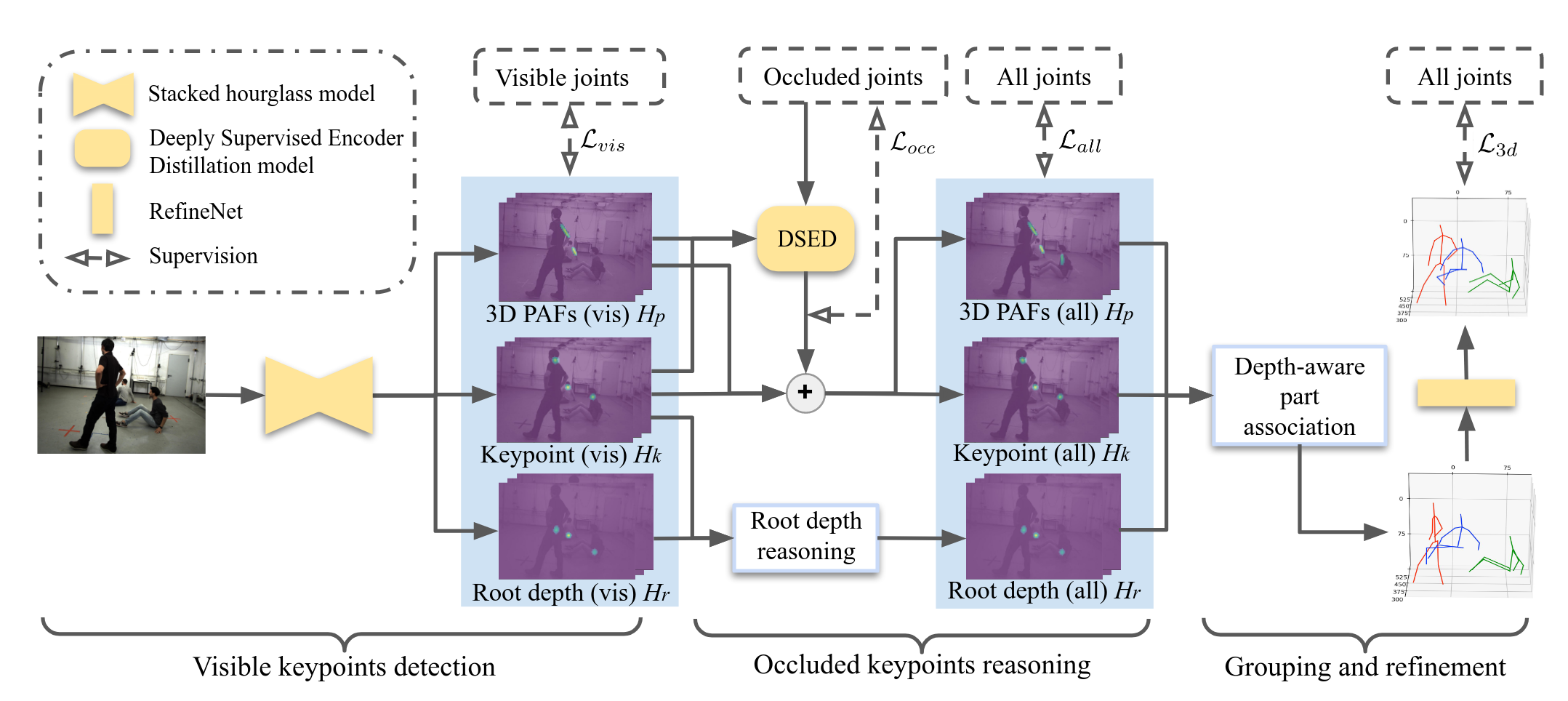 Explicit Occlusion Reasoning for Multi-person 3D Human Pose EstimationQihao Liu, Yi Zhang, Song Bai, and Alan YuilleIn ECCV 2022
Explicit Occlusion Reasoning for Multi-person 3D Human Pose EstimationQihao Liu, Yi Zhang, Song Bai, and Alan YuilleIn ECCV 2022Occlusion poses a great threat to monocular multi-person 3D human poseestimation due to large variability in terms of the shape, appearance, andposition of occluders. While existing methods try to handle occlusion with posepriors/constraints, data augmentation, or implicit reasoning, they still failto generalize to unseen poses or occlusion cases and may make large mistakeswhen multiple people are present. Inspired by the remarkable ability of humansto infer occluded joints from visible cues, we develop a method to explicitlymodel this process that significantly improves bottom-up multi-person humanpose estimation with or without occlusions. First, we split the task into twosubtasks: visible keypoints detection and occluded keypoints reasoning, andpropose a Deeply Supervised Encoder Distillation (DSED) network to solve thesecond one. To train our model, we propose a Skeleton-guided human ShapeFitting (SSF) approach to generate pseudo occlusion labels on the existingdatasets, enabling explicit occlusion reasoning. Experiments show thatexplicitly learning from occlusions improves human pose estimation. Inaddition, exploiting feature-level information of visible joints allows us toreason about occluded joints more accurately. Our method outperforms both thestate-of-the-art top-down and bottom-up methods on several benchmarks.
估计被遮挡住的数据然后再进行association
human-pose-estimation 1vmp@inproceedings{Occulusion_reasoning, title = {Explicit Occlusion Reasoning for Multi-person 3D Human Pose Estimation}, author = {Liu, Qihao and Zhang, Yi and Bai, Song and Yuille, Alan}, year = {2022}, tags = {human-pose-estimation, 1vmp}, booktitle = {ECCV}, }
2021
-
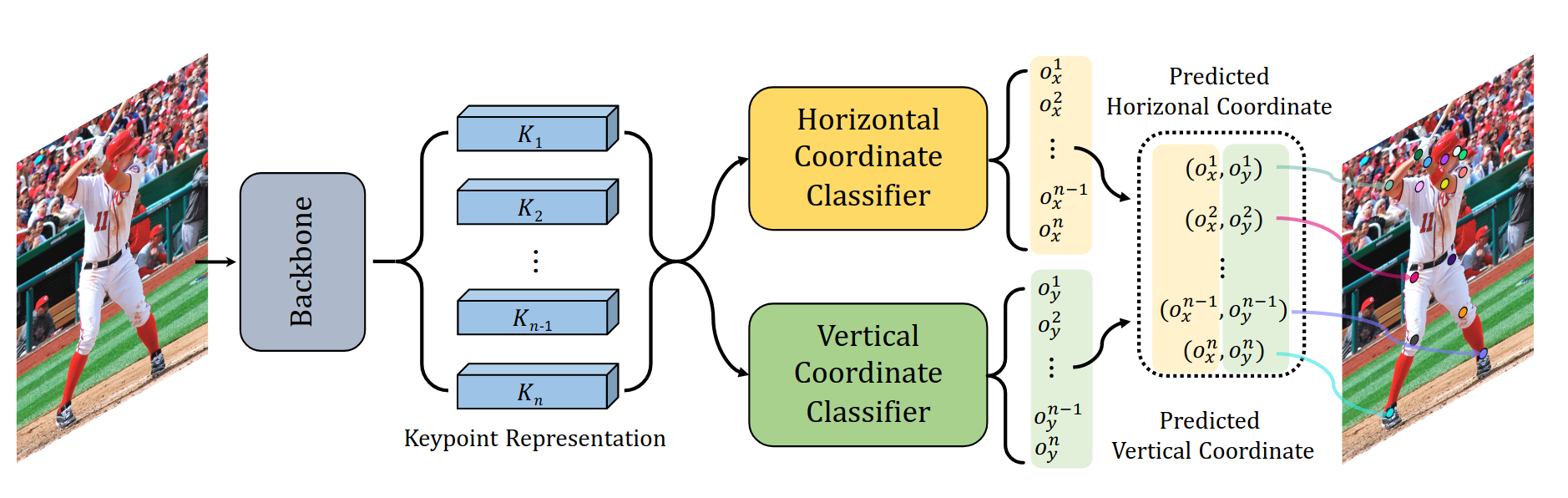 SimCC: a Simple Coordinate Classification Perspective for Human Pose EstimationYanjie Li, Sen Yang, Peidong Liu, Shoukui Zhang, Yunxiao Wang, Zhicheng Wang, Wankou Yang, and Shu-Tao XiaIn ECCV 2021
SimCC: a Simple Coordinate Classification Perspective for Human Pose EstimationYanjie Li, Sen Yang, Peidong Liu, Shoukui Zhang, Yunxiao Wang, Zhicheng Wang, Wankou Yang, and Shu-Tao XiaIn ECCV 2021The 2D heatmap-based approaches have dominated Human Pose Estimation (HPE)for years due to high performance. However, the long-standing quantizationerror problem in the 2D heatmap-based methods leads to several well-knowndrawbacks: 1) The performance for the low-resolution inputs is limited; 2) Toimprove the feature map resolution for higher localization precision, multiplecostly upsampling layers are required; 3) Extra post-processing is adopted toreduce the quantization error. To address these issues, we aim to explore abrand new scheme, called \textitSimCC, which reformulates HPE as twoclassification tasks for horizontal and vertical coordinates. The proposedSimCC uniformly divides each pixel into several bins, thus achieving\emphsub-pixel localization precision and low quantization error. Benefitingfrom that, SimCC can omit additional refinement post-processing and excludeupsampling layers under certain settings, resulting in a more simple andeffective pipeline for HPE. Extensive experiments conducted over COCO,CrowdPose, and MPII datasets show that SimCC outperforms heatmap-basedcounterparts, especially in low-resolution settings by a large margin.
从坐标分类的角度来看2D人体姿态估计问题
human-pose-estimation@inproceedings{SimCC, title = {SimCC: a Simple Coordinate Classification Perspective for Human Pose Estimation}, author = {Li, Yanjie and Yang, Sen and Liu, Peidong and Zhang, Shoukui and Wang, Yunxiao and Wang, Zhicheng and Yang, Wankou and Xia, Shu-Tao}, year = {2021}, tags = {human-pose-estimation}, booktitle = {ECCV}, }