mp
Papers with tag mp
2022
- VTP: Volumetric Transformer for Multi-view Multi-person 3D Pose EstimationYuxing Chen, Renshu Gu, Ouhan Huang, and Gangyong JiaIn 2022
This paper presents Volumetric Transformer Pose estimator (VTP), the first 3Dvolumetric transformer framework for multi-view multi-person 3D human poseestimation. VTP aggregates features from 2D keypoints in all camera views anddirectly learns the spatial relationships in the 3D voxel space in anend-to-end fashion. The aggregated 3D features are passed through 3Dconvolutions before being flattened into sequential embeddings and fed into atransformer. A residual structure is designed to further improve theperformance. In addition, the sparse Sinkhorn attention is empowered to reducethe memory cost, which is a major bottleneck for volumetric representations,while also achieving excellent performance. The output of the transformer isagain concatenated with 3D convolutional features by a residual design. Theproposed VTP framework integrates the high performance of the transformer withvolumetric representations, which can be used as a good alternative to theconvolutional backbones. Experiments on the Shelf, Campus and CMU Panopticbenchmarks show promising results in terms of both Mean Per Joint PositionError (MPJPE) and Percentage of Correctly estimated Parts (PCP). Our code willbe available.
使用3DVolTransformer回归人体坐标
human mv mp 3dpose transformer@inproceedings{VTP, title = {VTP: Volumetric Transformer for Multi-view Multi-person 3D Pose Estimation}, author = {Chen, Yuxing and Gu, Renshu and Huang, Ouhan and Jia, Gangyong}, year = {2022}, tags = {human, mv, mp, 3dpose, transformer}, } - FIND: An Unsupervised Implicit 3D Model of Articulated Human FeetOliver Boyne, James Charles, and Roberto CipollaIn 2022
In this paper we present a high fidelity and articulated 3D human foot model.The model is parameterised by a disentangled latent code in terms of shape,texture and articulated pose. While high fidelity models are typically createdwith strong supervision such as 3D keypoint correspondences orpre-registration, we focus on the difficult case of little to no annotation. Tothis end, we make the following contributions: (i) we develop a Foot ImplicitNeural Deformation field model, named FIND, capable of tailoring explicitmeshes at any resolution i.e. for low or high powered devices; (ii) an approachfor training our model in various modes of weak supervision with progressivelybetter disentanglement as more labels, such as pose categories, are provided;(iii) a novel unsupervised part-based loss for fitting our model to 2D imageswhich is better than traditional photometric or silhouette losses; (iv)finally, we release a new dataset of high resolution 3D human foot scans,Foot3D. On this dataset, we show our model outperforms a strong PCAimplementation trained on the same data in terms of shape quality and partcorrespondences, and that our novel unsupervised part-based loss improvesinference on images.
使用RGB来自监督的训练脚的隐式表达
human feet human-representation implicit-model@inproceedings{FIND, title = {FIND: An Unsupervised Implicit 3D Model of Articulated Human Feet}, author = {Boyne, Oliver and Charles, James and Cipolla, Roberto}, year = {2022}, tags = {human, feet, human-representation, implicit-model}, } - ARAH: Animatable Volume Rendering of Articulated Human SDFsShaofei Wang, Katja Schwarz, Andreas Geiger, and Siyu TangIn 2022
Combining human body models with differentiable rendering has recentlyenabled animatable avatars of clothed humans from sparse sets of multi-view RGBvideos. While state-of-the-art approaches achieve realistic appearance withneural radiance fields (NeRF), the inferred geometry often lacks detail due tomissing geometric constraints. Further, animating avatars inout-of-distribution poses is not yet possible because the mapping fromobservation space to canonical space does not generalize faithfully to unseenposes. In this work, we address these shortcomings and propose a model tocreate animatable clothed human avatars with detailed geometry that generalizewell to out-of-distribution poses. To achieve detailed geometry, we combine anarticulated implicit surface representation with volume rendering. Forgeneralization, we propose a novel joint root-finding algorithm forsimultaneous ray-surface intersection search and correspondence search. Ouralgorithm enables efficient point sampling and accurate point canonicalizationwhile generalizing well to unseen poses. We demonstrate that our proposedpipeline can generate clothed avatars with high-quality pose-dependent geometryand appearance from a sparse set of multi-view RGB videos. Our method achievesstate-of-the-art performance on geometry and appearance reconstruction whilecreating animatable avatars that generalize well to out-of-distribution posesbeyond the small number of training poses.
clothed implicit neural-rendering@inproceedings{ARAH, title = {ARAH: Animatable Volume Rendering of Articulated Human SDFs}, author = {Wang, Shaofei and Schwarz, Katja and Geiger, Andreas and Tang, Siyu}, year = {2022}, tags = {clothed, implicit, neural-rendering}, } -
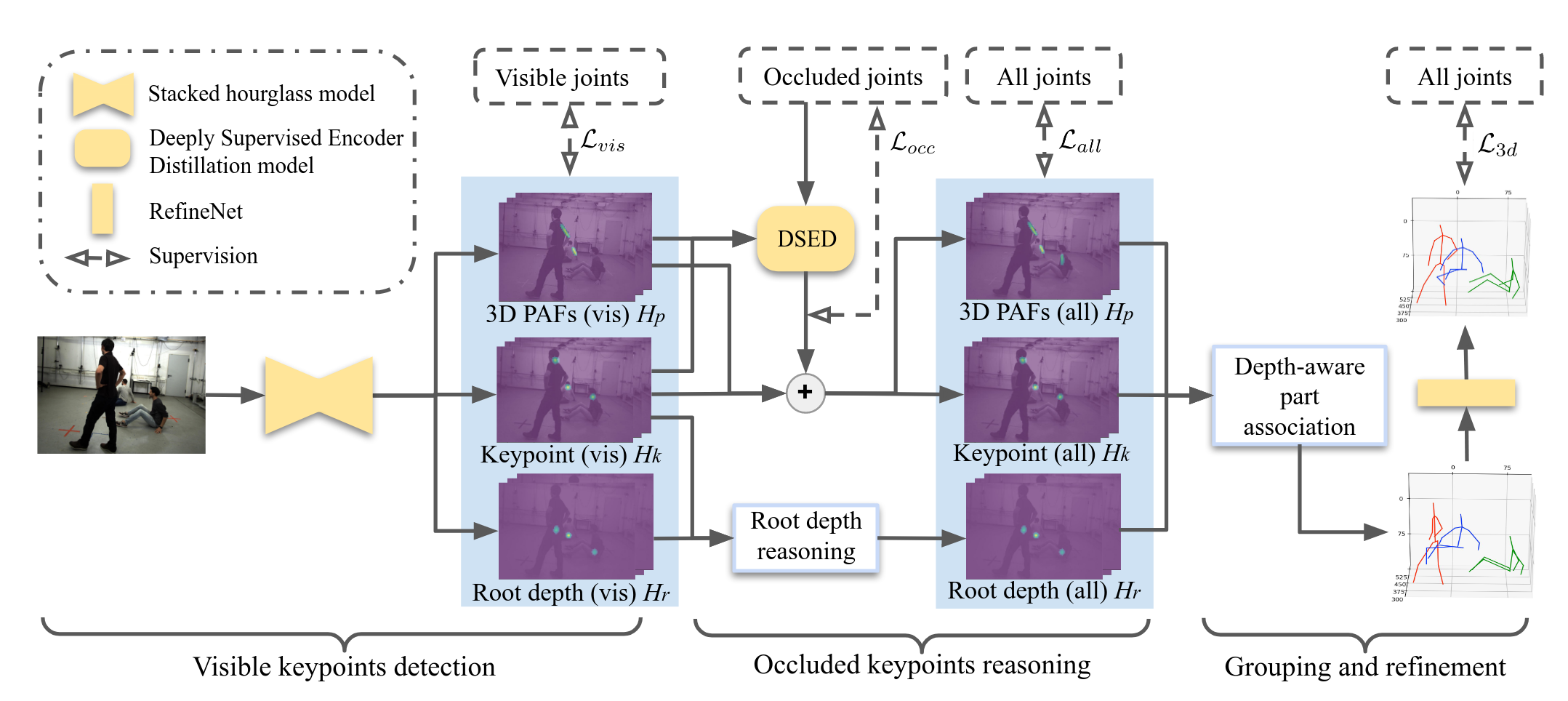 Explicit Occlusion Reasoning for Multi-person 3D Human Pose EstimationQihao Liu, Yi Zhang, Song Bai, and Alan YuilleIn ECCV 2022
Explicit Occlusion Reasoning for Multi-person 3D Human Pose EstimationQihao Liu, Yi Zhang, Song Bai, and Alan YuilleIn ECCV 2022Occlusion poses a great threat to monocular multi-person 3D human poseestimation due to large variability in terms of the shape, appearance, andposition of occluders. While existing methods try to handle occlusion with posepriors/constraints, data augmentation, or implicit reasoning, they still failto generalize to unseen poses or occlusion cases and may make large mistakeswhen multiple people are present. Inspired by the remarkable ability of humansto infer occluded joints from visible cues, we develop a method to explicitlymodel this process that significantly improves bottom-up multi-person humanpose estimation with or without occlusions. First, we split the task into twosubtasks: visible keypoints detection and occluded keypoints reasoning, andpropose a Deeply Supervised Encoder Distillation (DSED) network to solve thesecond one. To train our model, we propose a Skeleton-guided human ShapeFitting (SSF) approach to generate pseudo occlusion labels on the existingdatasets, enabling explicit occlusion reasoning. Experiments show thatexplicitly learning from occlusions improves human pose estimation. Inaddition, exploiting feature-level information of visible joints allows us toreason about occluded joints more accurately. Our method outperforms both thestate-of-the-art top-down and bottom-up methods on several benchmarks.
估计被遮挡住的数据然后再进行association
human-pose-estimation 1vmp@inproceedings{Occulusion_reasoning, title = {Explicit Occlusion Reasoning for Multi-person 3D Human Pose Estimation}, author = {Liu, Qihao and Zhang, Yi and Bai, Song and Yuille, Alan}, year = {2022}, tags = {human-pose-estimation, 1vmp}, booktitle = {ECCV}, }
2021
- Direct Multi-view Multi-person 3D Pose EstimationTao Wang, Jianfeng Zhang, Yujun Cai, Shuicheng Yan, and Jiashi FengIn 2021
We present Multi-view Pose transformer (MvP) for estimating multi-person 3Dposes from multi-view images. Instead of estimating 3D joint locations fromcostly volumetric representation or reconstructing the per-person 3D pose frommultiple detected 2D poses as in previous methods, MvP directly regresses themulti-person 3D poses in a clean and efficient way, without relying onintermediate tasks. Specifically, MvP represents skeleton joints as learnablequery embeddings and let them progressively attend to and reason over themulti-view information from the input images to directly regress the actual 3Djoint locations. To improve the accuracy of such a simple pipeline, MvPpresents a hierarchical scheme to concisely represent query embeddings ofmulti-person skeleton joints and introduces an input-dependent query adaptationapproach. Further, MvP designs a novel geometrically guided attentionmechanism, called projective attention, to more precisely fuse the cross-viewinformation for each joint. MvP also introduces a RayConv operation tointegrate the view-dependent camera geometry into the feature representationsfor augmenting the projective attention. We show experimentally that our MvPmodel outperforms the state-of-the-art methods on several benchmarks whilebeing much more efficient. Notably, it achieves 92.3% AP25 on the challengingPanoptic dataset, improving upon the previous best approach [36] by 9.8%. MvPis general and also extendable to recovering human mesh represented by the SMPLmodel, thus useful for modeling multi-person body shapes. Code and models areavailable at https://github.com/sail-sg/mvp.
多视角的feature直接通过transformer聚合
human mv mp 3dpose transformer@inproceedings{DMVMP, title = {Direct Multi-view Multi-person 3D Pose Estimation}, author = {Wang, Tao and Zhang, Jianfeng and Cai, Yujun and Yan, Shuicheng and Feng, Jiashi}, year = {2021}, tags = {human, mv, mp, 3dpose, transformer}, } - Graph-Based 3D Multi-Person Pose Estimation Using Multi-View ImagesSize Wu, Sheng Jin, Wentao Liu, Lei Bai, Chen Qian, Dong Liu, and Wanli OuyangIn 2021
This paper studies the task of estimating the 3D human poses of multiplepersons from multiple calibrated camera views. Following the top-down paradigm,we decompose the task into two stages, i.e. person localization and poseestimation. Both stages are processed in coarse-to-fine manners. And we proposethree task-specific graph neural networks for effective message passing. For 3Dperson localization, we first use Multi-view Matching Graph Module (MMG) tolearn the cross-view association and recover coarse human proposals. The CenterRefinement Graph Module (CRG) further refines the results via flexiblepoint-based prediction. For 3D pose estimation, the Pose Regression GraphModule (PRG) learns both the multi-view geometry and structural relationsbetween human joints. Our approach achieves state-of-the-art performance on CMUPanoptic and Shelf datasets with significantly lower computation complexity.
通过图网络来学习多人对应关系
human mv mp 3dpose GNN@inproceedings{graphmp, title = {Graph-Based 3D Multi-Person Pose Estimation Using Multi-View Images}, author = {Wu, Size and Jin, Sheng and Liu, Wentao and Bai, Lei and Qian, Chen and Liu, Dong and Ouyang, Wanli}, year = {2021}, tags = {human, mv, mp, 3dpose, GNN}, }
2020
2019
2018
- Self-supervised Multi-view Person Association and Its ApplicationsMinh Vo, Ersin Yumer, Kalyan Sunkavalli, Sunil Hadap, Yaser Sheikh, and Srinivasa NarasimhanIn 2018
Reliable markerless motion tracking of people participating in a complexgroup activity from multiple moving cameras is challenging due to frequentocclusions, strong viewpoint and appearance variations, and asynchronous videostreams. To solve this problem, reliable association of the same person acrossdistant viewpoints and temporal instances is essential. We present aself-supervised framework to adapt a generic person appearance descriptor tothe unlabeled videos by exploiting motion tracking, mutual exclusionconstraints, and multi-view geometry. The adapted discriminative descriptor isused in a tracking-by-clustering formulation. We validate the effectiveness ofour descriptor learning on WILDTRACK [14] and three new complex social scenescaptured by multiple cameras with up to 60 people "in the wild". We reportsignificant improvement in association accuracy (up to 18%) and stable andcoherent 3D human skeleton tracking (5 to 10 times) over the baseline. Usingthe reconstructed 3D skeletons, we cut the input videos into a multi-anglevideo where the image of a specified person is shown from the best visiblefront-facing camera. Our algorithm detects inter-human occlusion to determinethe camera switching moment while still maintaining the flow of the actionwell.
自监督的特征学习进行人体的聚类
human mv mp 3dpose self-supervised@inproceedings{MVPAssociation, title = {Self-supervised Multi-view Person Association and Its Applications}, author = {Vo, Minh and Yumer, Ersin and Sunkavalli, Kalyan and Hadap, Sunil and Sheikh, Yaser and Narasimhan, Srinivasa}, year = {2018}, tags = {human, mv, mp, 3dpose, self-supervised}, }