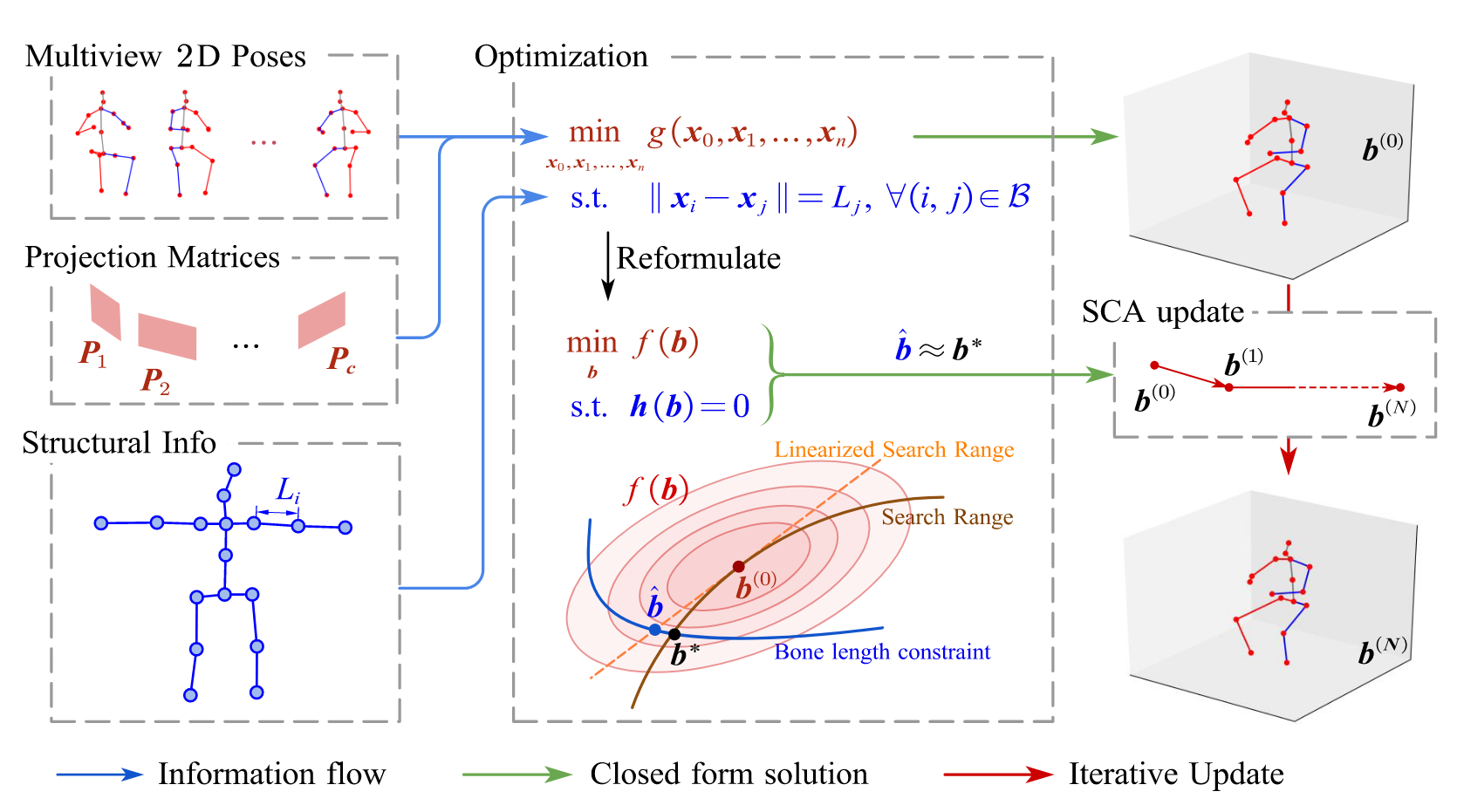
@inproceedings{Structural_Triangulation,title={Structural Triangulation: A Closed-Form Solution to Constrained 3D Human Pose Estimation},author={},year={2022},tags={mv1p},booktitle={ECCV},}
The increasing availability of video recordings made by multiple cameras hasoffered new means for mitigating occlusion and depth ambiguities in pose andmotion reconstruction methods. Yet, multi-view algorithms strongly depend oncamera parameters; particularly, the relative transformations between thecameras. Such a dependency becomes a hurdle once shifting to dynamic capture inuncontrolled settings. We introduce FLEX (Free muLti-view rEconstruXion), anend-to-end extrinsic parameter-free multi-view model. FLEX is extrinsicparameter-free (dubbed ep-free) in the sense that it does not require extrinsiccamera parameters. Our key idea is that the 3D angles between skeletal parts,as well as bone lengths, are invariant to the camera position. Hence, learning3D rotations and bone lengths rather than locations allows predicting commonvalues for all camera views. Our network takes multiple video streams, learnsfused deep features through a novel multi-view fusion layer, and reconstructs asingle consistent skeleton with temporally coherent joint rotations. Wedemonstrate quantitative and qualitative results on three public datasets, andon synthetic multi-person video streams captured by dynamic cameras. We compareour model to state-of-the-art methods that are not ep-free and show that in theabsence of camera parameters, we outperform them by a large margin whileobtaining comparable results when camera parameters are available. Code,trained models, and other materials are available on our project page.
输入多视角的序列的2D估计,估计脚步接触标签以及骨长、3D旋转,可以不给定相机
@inproceedings{FLEX,title={FLEX: Extrinsic Parameters-free Multi-view 3D Human Motion Reconstruction},author={Gordon, Brian and Raab, Sigal and Azov, Guy and Giryes, Raja and Cohen-Or, Daniel},year={2021},tags={3dpose, mv1p},booktitle={ECCV},}