Paper Reading of Sida
2022
-
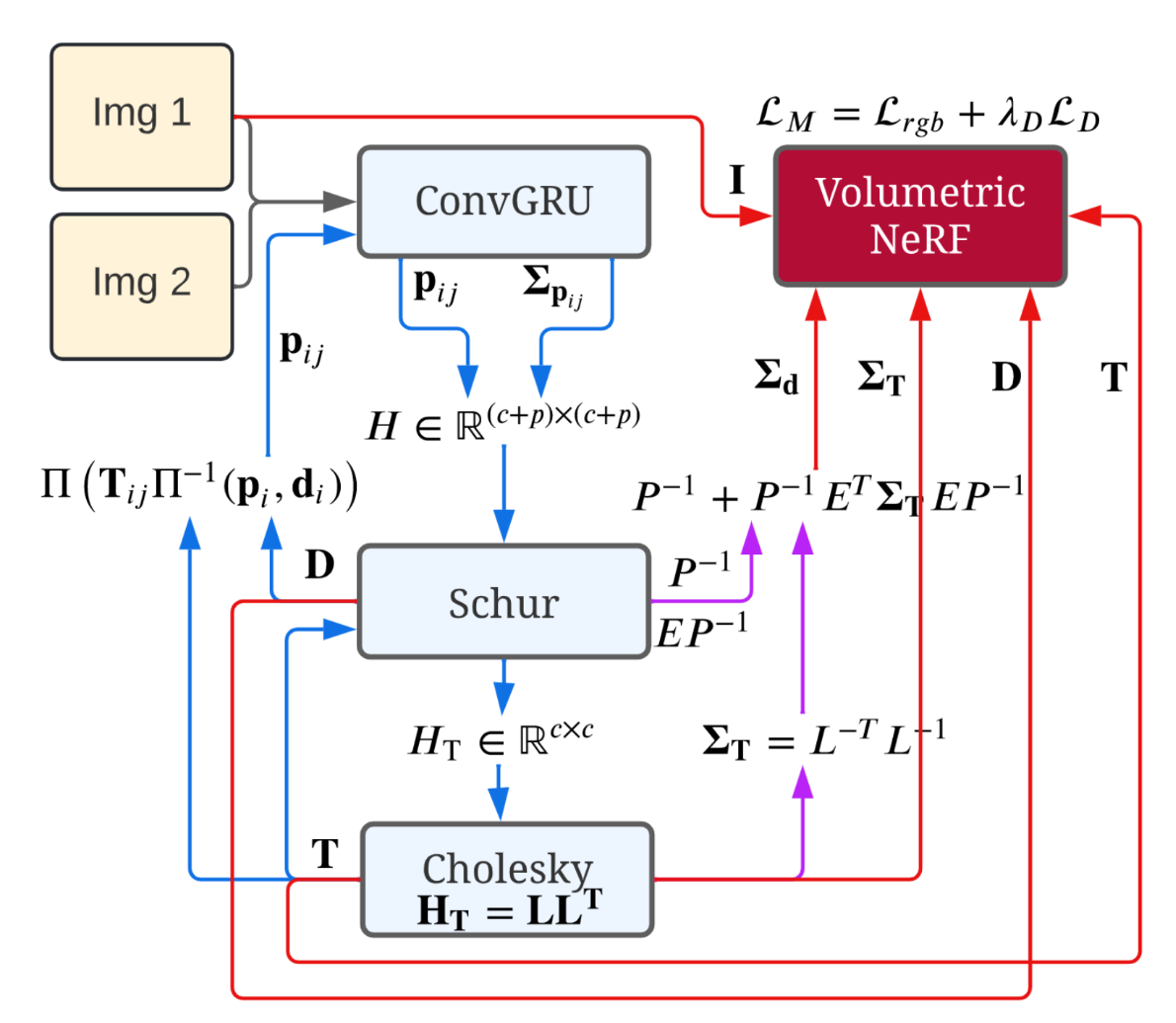 NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance FieldsAntoni Rosinol, John J. Leonard, and Luca CarloneIn 2022
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance FieldsAntoni Rosinol, John J. Leonard, and Luca CarloneIn 2022We propose a novel geometric and photometric 3D mapping pipeline for accurateand real-time scene reconstruction from monocular images. To achieve this, weleverage recent advances in dense monocular SLAM and real-time hierarchicalvolumetric neural radiance fields. Our insight is that dense monocular SLAMprovides the right information to fit a neural radiance field of the scene inreal-time, by providing accurate pose estimates and depth-maps with associateduncertainty. With our proposed uncertainty-based depth loss, we achieve notonly good photometric accuracy, but also great geometric accuracy. In fact, ourproposed pipeline achieves better geometric and photometric accuracy thancompeting approaches (up to 179% better PSNR and 86% better L1 depth), whileworking in real-time and using only monocular images.
Real-time dense monocular SLAM. 将monocular SLAM和volumetric nerf结合. SLAM提供camera poses, depth maps和uncertainty用于volumetric nerf的训练.
@inproceedings{NeRFSLAM, title = {NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields}, author = {Rosinol, Antoni and Leonard, John J. and Carlone, Luca}, year = {2022}, sida = {Real-time dense monocular SLAM. 将monocular SLAM和volumetric nerf结合. SLAM提供camera poses, depth maps和uncertainty用于volumetric nerf的训练.}, } - Multi-Person 3D Pose and Shape Estimation via Inverse Kinematics and RefinementJunuk Cha, Muhammad Saqlain, GeonU Kim, Mingyu Shin, and Seungryul BaekIn 2022
Estimating 3D poses and shapes in the form of meshes from monocular RGBimages is challenging. Obviously, it is more difficult than estimating 3D posesonly in the form of skeletons or heatmaps. When interacting persons areinvolved, the 3D mesh reconstruction becomes more challenging due to theambiguity introduced by person-to-person occlusions. To tackle the challenges,we propose a coarse-to-fine pipeline that benefits from 1) inverse kinematicsfrom the occlusion-robust 3D skeleton estimation and 2) Transformer-basedrelation-aware refinement techniques. In our pipeline, we first obtainocclusion-robust 3D skeletons for multiple persons from an RGB image. Then, weapply inverse kinematics to convert the estimated skeletons to deformable 3Dmesh parameters. Finally, we apply the Transformer-based mesh refinement thatrefines the obtained mesh parameters considering intra- and inter-personrelations of 3D meshes. Via extensive experiments, we demonstrate theeffectiveness of our method, outperforming state-of-the-arts on 3DPW, MuPoTSand AGORA datasets.
Multi-person human mesh recovery from monocular images. 预测multi-person skeleton, 然后用inverse kinematics得到SMPL parameters.
@inproceedings{MPviaIK, title = {Multi-Person 3D Pose and Shape Estimation via Inverse Kinematics and Refinement}, author = {Cha, Junuk and Saqlain, Muhammad and Kim, GeonU and Shin, Mingyu and Baek, Seungryul}, year = {2022}, sida = {Multi-person human mesh recovery from monocular images. 预测multi-person skeleton, 然后用inverse kinematics得到SMPL parameters.}, } - SUPR: A Sparse Unified Part-Based Human RepresentationAhmed A. A. Osman, Timo Bolkart, Dimitrios Tzionas, and Michael J. BlackIn 2022
Statistical 3D shape models of the head, hands, and fullbody are widely usedin computer vision and graphics. Despite their wide use, we show that existingmodels of the head and hands fail to capture the full range of motion for theseparts. Moreover, existing work largely ignores the feet, which are crucial formodeling human movement and have applications in biomechanics, animation, andthe footwear industry. The problem is that previous body part models aretrained using 3D scans that are isolated to the individual parts. Such datadoes not capture the full range of motion for such parts, e.g. the motion ofhead relative to the neck. Our observation is that full-body scans provideimportant information about the motion of the body parts. Consequently, wepropose a new learning scheme that jointly trains a full-body model andspecific part models using a federated dataset of full-body and body-partscans. Specifically, we train an expressive human body model called SUPR(Sparse Unified Part-Based Human Representation), where each joint strictlyinfluences a sparse set of model vertices. The factorized representationenables separating SUPR into an entire suite of body part models. Note that thefeet have received little attention and existing 3D body models have highlyunder-actuated feet. Using novel 4D scans of feet, we train a model with anextended kinematic tree that captures the range of motion of the toes.Additionally, feet deform due to ground contact. To model this, we include anovel non-linear deformation function that predicts foot deformationconditioned on the foot pose, shape, and ground contact. We train SUPR on anunprecedented number of scans: 1.2 million body, head, hand and foot scans. Wequantitatively compare SUPR and the separated body parts and find that oursuite of models generalizes better than existing models. SUPR is available athttp://supr.is.tue.mpg.de
基于part的人体模型
human human-part human-representation@inproceedings{SUPR, title = {SUPR: A Sparse Unified Part-Based Human Representation}, author = {Osman, Ahmed A. A. and Bolkart, Timo and Tzionas, Dimitrios and Black, Michael J.}, year = {2022}, tags = {human, human-part, human-representation}, } - DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to RealityAnkur Handa, Arthur Allshire, Viktor Makoviychuk, Aleksei Petrenko, Ritvik Singh, Jingzhou Liu, Denys Makoviichuk, Karl Van Wyk, Alexander Zhurkevich, Balakumar Sundaralingam, and 4 more authorsIn 2022
Recent work has demonstrated the ability of deep reinforcement learning (RL)algorithms to learn complex robotic behaviours in simulation, including in thedomain of multi-fingered manipulation. However, such models can be challengingto transfer to the real world due to the gap between simulation and reality. Inthis paper, we present our techniques to train a) a policy that can performrobust dexterous manipulation on an anthropomorphic robot hand and b) a robustpose estimator suitable for providing reliable real-time information on thestate of the object being manipulated. Our policies are trained to adapt to awide range of conditions in simulation. Consequently, our vision-based policiessignificantly outperform the best vision policies in the literature on the samereorientation task and are competitive with policies that are given privilegedstate information via motion capture systems. Our work reaffirms thepossibilities of sim-to-real transfer for dexterous manipulation in diversekinds of hardware and simulator setups, and in our case, with the Allegro Handand Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities forresearchers to achieve such results with commonly-available, affordable robothands and cameras. Videos of the resulting policy and supplementaryinformation, including experiments and demos, can be found at\urlhttps://dextreme.org/
Dexterous manipulation. 在大量simulation environments下训练学习policy, 实现sim-to-real transfer.
@inproceedings{DeXtreme, title = {DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality}, author = {Handa, Ankur and Allshire, Arthur and Makoviychuk, Viktor and Petrenko, Aleksei and Singh, Ritvik and Liu, Jingzhou and Makoviichuk, Denys and Wyk, Karl Van and Zhurkevich, Alexander and Sundaralingam, Balakumar and Narang, Yashraj and Lafleche, Jean-Francois and Fox, Dieter and State, Gavriel}, year = {2022}, sida = {Dexterous manipulation. 在大量simulation environments下训练学习policy, 实现sim-to-real transfer.}, } - Motion Policy NetworksAdam Fishman, Adithyavairan Murali, Clemens Eppner, Bryan Peele, Byron Boots, and Dieter FoxIn 2022
Collision-free motion generation in unknown environments is a core buildingblock for robot manipulation. Generating such motions is challenging due tomultiple objectives; not only should the solutions be optimal, the motiongenerator itself must be fast enough for real-time performance and reliableenough for practical deployment. A wide variety of methods have been proposedranging from local controllers to global planners, often being combined tooffset their shortcomings. We present an end-to-end neural model called MotionPolicy Networks (M\piNets) to generate collision-free, smooth motion fromjust a single depth camera observation. M\piNets are trained on over 3million motion planning problems in over 500,000 environments. Our experimentsshow that M\piNets are significantly faster than global planners whileexhibiting the reactivity needed to deal with dynamic scenes. They are 46%better than prior neural planners and more robust than local control policies.Despite being only trained in simulation, M\piNets transfer well to the realrobot with noisy partial point clouds. Code and data are publicly available athttps://mpinets.github.io.
Collision-free motion generation in unknown environments. 提出一个simulation datasets, 训练一个motion policy networks, 从single depth observation预测smooth motion.
@inproceedings{Motion_Policy_Networks, title = {Motion Policy Networks}, author = {Fishman, Adam and Murali, Adithyavairan and Eppner, Clemens and Peele, Bryan and Boots, Byron and Fox, Dieter}, year = {2022}, sida = {Collision-free motion generation in unknown environments. 提出一个simulation datasets, 训练一个motion policy networks, 从single depth observation预测smooth motion.}, } - Streaming Radiance Fields for 3D Video SynthesisLingzhi Li, Zhen Shen, Zhongshu Wang, Li Shen, and Ping TanIn 2022
We present an explicit-grid based method for efficiently reconstructingstreaming radiance fields for novel view synthesis of real world dynamicscenes. Instead of training a single model that combines all the frames, weformulate the dynamic modeling problem with an incremental learning paradigm inwhich per-frame model difference is trained to complement the adaption of abase model on the current frame. By exploiting the simple yet effective tuningstrategy with narrow bands, the proposed method realizes a feasible frameworkfor handling video sequences on-the-fly with high training efficiency. Thestorage overhead induced by using explicit grid representations can besignificantly reduced through the use of model difference based compression. Wealso introduce an efficient strategy to further accelerate model optimizationfor each frame. Experiments on challenging video sequences demonstrate that ourapproach is capable of achieving a training speed of 15 seconds per-frame withcompetitive rendering quality, which attains 1000 \times speedup over thestate-of-the-art implicit methods. Code is available athttps://github.com/AlgoHunt/StreamRF.
提升训练速度. 提出一个explicit-grid based method, 将3d videos表示为a based model and per-frame model difference.
neural-3d-videos@inproceedings{Streaming_RF, title = {Streaming Radiance Fields for 3D Video Synthesis}, author = {Li, Lingzhi and Shen, Zhen and Wang, Zhongshu and Shen, Li and Tan, Ping}, year = {2022}, tags = {neural-3d-videos}, sida = {提升训练速度. 提出一个explicit-grid based method, 将3d videos表示为a based model and per-frame model difference.}, } - Boosting Point Clouds Rendering via Radiance MappingXiaoyang Huang, Yi Zhang, Bingbing Ni, Teng Li, Kai Chen, and Wenjun ZhangIn 2022
Recent years we have witnessed rapid development in NeRF-based imagerendering due to its high quality. However, point clouds rendering is somehowless explored. Compared to NeRF-based rendering which suffers from densespatial sampling, point clouds rendering is naturally less computationintensive, which enables its deployment in mobile computing device. In thiswork, we focus on boosting the image quality of point clouds rendering with acompact model design. We first analyze the adaption of the volume renderingformulation on point clouds. Based on the analysis, we simplify the NeRFrepresentation to a spatial mapping function which only requires singleevaluation per pixel. Further, motivated by ray marching, we rectify the thenoisy raw point clouds to the estimated intersection between rays and surfacesas queried coordinates, which could avoid spatial frequency collapse andneighbor point disturbance. Composed of rasterization, spatial mapping and therefinement stages, our method achieves the state-of-the-art performance onpoint clouds rendering, outperforming prior works by notable margins, with asmaller model size. We obtain a PSNR of 31.74 on NeRF-Synthetic, 25.88 onScanNet and 30.81 on DTU. Code and data would be released soon.
基于point cloud做rendering, 实现每条ray一次evaluation.
view-synthesis point-cloud@inproceedings{boosting_pc_render, title = {Boosting Point Clouds Rendering via Radiance Mapping}, author = {Huang, Xiaoyang and Zhang, Yi and Ni, Bingbing and Li, Teng and Chen, Kai and Zhang, Wenjun}, year = {2022}, tags = {view-synthesis, point-cloud}, sida = {基于point cloud做rendering, 实现每条ray一次evaluation.}, } - SAM-RL: Sensing-Aware Model-Based Reinforcement Learning via Differentiable Physics-Based Simulation and RenderingJun Lv, Yunhai Feng, Cheng Zhang, Shuang Zhao, Lin Shao, and Cewu LuIn 2022
Model-based reinforcement learning (MBRL) is recognized with the potential tobe significantly more sample efficient than model-free RL. How an accuratemodel can be developed automatically and efficiently from raw sensory inputs(such as images), especially for complex environments and tasks, is achallenging problem that hinders the broad application of MBRL in the realworld. In this work, we propose a sensing-aware model-based reinforcementlearning system called SAM-RL. Leveraging the differentiable physics-basedsimulation and rendering, SAM-RL automatically updates the model by comparingrendered images with real raw images and produces the policy efficiently. Withthe sensing-aware learning pipeline, SAM-RL allows a robot to select aninformative viewpoint to monitor the task process. We apply our framework toreal-world experiments for accomplishing three manipulation tasks: roboticassembly, tool manipulation, and deformable object manipulation. We demonstratethe effectiveness of SAM-RL via extensive experiments. Supplemental materialsand videos are available on our project webpage athttps://sites.google.com/view/sam-rl.
基于differentiable rendering更新environment model, 帮助model-based reinforcement learning.
manipulation differentiable-rendering@inproceedings{SAM-RL, title = {SAM-RL: Sensing-Aware Model-Based Reinforcement Learning via Differentiable Physics-Based Simulation and Rendering}, author = {Lv, Jun and Feng, Yunhai and Zhang, Cheng and Zhao, Shuang and Shao, Lin and Lu, Cewu}, year = {2022}, tags = {manipulation, differentiable-rendering}, sida = {基于differentiable rendering更新environment model, 帮助model-based reinforcement learning.}, } - NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance FieldsLiangchen Song, Anpei Chen, Zhong Li, Zhang Chen, Lele Chen, Junsong Yuan, Yi Xu, and Andreas GeigerIn 2022
Visually exploring in a real-world 4D spatiotemporal space freely in VR hasbeen a long-term quest. The task is especially appealing when only a few oreven single RGB cameras are used for capturing the dynamic scene. To this end,we present an efficient framework capable of fast reconstruction, compactmodeling, and streamable rendering. First, we propose to decompose the 4Dspatiotemporal space according to temporal characteristics. Points in the 4Dspace are associated with probabilities of belonging to three categories:static, deforming, and new areas. Each area is represented and regularized by aseparate neural field. Second, we propose a hybrid representations basedfeature streaming scheme for efficiently modeling the neural fields. Ourapproach, coined NeRFPlayer, is evaluated on dynamic scenes captured by singlehand-held cameras and multi-camera arrays, achieving comparable or superiorrendering performance in terms of quality and speed comparable to recentstate-of-the-art methods, achieving reconstruction in 10 seconds per frame andreal-time rendering.
用一个hybrid representation-based feature streaming scheme表示动态场景.
neural-3d-videos@inproceedings{NeRFPlayer, title = {NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields}, author = {Song, Liangchen and Chen, Anpei and Li, Zhong and Chen, Zhang and Chen, Lele and Yuan, Junsong and Xu, Yi and Geiger, Andreas}, year = {2022}, tags = {neural-3d-videos}, sida = {用一个hybrid representation-based feature streaming scheme表示动态场景.}, } - ProbNeRF: Uncertainty-Aware Inference of 3D Shapes from 2D ImagesMatthew D. Hoffman, Tuan Anh Le, Pavel Sountsov, Christopher Suter, Ben Lee, Vikash K. Mansinghka, and Rif A. SaurousIn 2022
The problem of inferring object shape from a single 2D image isunderconstrained. Prior knowledge about what objects are plausible can help,but even given such prior knowledge there may still be uncertainty about theshapes of occluded parts of objects. Recently, conditional neural radiancefield (NeRF) models have been developed that can learn to infer good pointestimates of 3D models from single 2D images. The problem of inferringuncertainty estimates for these models has received less attention. In thiswork, we propose probabilistic NeRF (ProbNeRF), a model and inference strategyfor learning probabilistic generative models of 3D objects’ shapes andappearances, and for doing posterior inference to recover those properties from2D images. ProbNeRF is trained as a variational autoencoder, but at test timewe use Hamiltonian Monte Carlo (HMC) for inference. Given one or a few 2Dimages of an object (which may be partially occluded), ProbNeRF is able notonly to accurately model the parts it sees, but also to propose realistic anddiverse hypotheses about the parts it does not see. We show that key to thesuccess of ProbNeRF are (i) a deterministic rendering scheme, (ii) anannealed-HMC strategy, (iii) a hypernetwork-based decoder architecture, and(iv) doing inference over a full set of NeRF weights, rather than just alow-dimensional code.
Single-view shape reconstruction. 用variational autoencoder训练一个generative model, 用Monte Carlo预测图片的latent vector.
@inproceedings{ProbNerf, title = {ProbNeRF: Uncertainty-Aware Inference of 3D Shapes from 2D Images}, author = {Hoffman, Matthew D. and Le, Tuan Anh and Sountsov, Pavel and Suter, Christopher and Lee, Ben and Mansinghka, Vikash K. and Saurous, Rif A.}, year = {2022}, } - gCoRF: Generative Compositional Radiance FieldsMallikarjun BR, Ayush Tewari, Xingang Pan, Mohamed Elgharib, and Christian TheobaltIn 2022
3D generative models of objects enable photorealistic image synthesis with 3Dcontrol. Existing methods model the scene as a global scene representation,ignoring the compositional aspect of the scene. Compositional reasoning canenable a wide variety of editing applications, in addition to enablinggeneralizable 3D reasoning. In this paper, we present a compositionalgenerative model, where each semantic part of the object is represented as anindependent 3D representation learned from only in-the-wild 2D data. We startwith a global generative model (GAN) and learn to decompose it into differentsemantic parts using supervision from 2D segmentation masks. We then learn tocomposite independently sampled parts in order to create coherent globalscenes. Different parts can be independently sampled while keeping the rest ofthe object fixed. We evaluate our method on a wide variety of objects and partsand demonstrate editing applications.
Editable 3D-aware generative model. 先学习一个global generative model, 然后通过semantic mask解藕为多个semantic part的generative models.
@inproceedings{gCoRF, title = {gCoRF: Generative Compositional Radiance Fields}, author = {BR, Mallikarjun and Tewari, Ayush and Pan, Xingang and Elgharib, Mohamed and Theobalt, Christian}, year = {2022}, sida = {Editable 3D-aware generative model. 先学习一个global generative model, 然后通过semantic mask解藕为多个semantic part的generative models.}, } - UmeTrack: Unified multi-view end-to-end hand tracking for VRShangchen Han, Po-chen Wu, Yubo Zhang, Beibei Liu, Linguang Zhang, Zheng Wang, Weiguang Si, Peizhao Zhang, Yujun Cai, Tomas Hodan, and 6 more authorsIn 2022
Real-time tracking of 3D hand pose in world space is a challenging problemand plays an important role in VR interaction. Existing work in this space arelimited to either producing root-relative (versus world space) 3D pose or relyon multiple stages such as generating heatmaps and kinematic optimization toobtain 3D pose. Moreover, the typical VR scenario, which involves multi-viewtracking from wide \acfov cameras is seldom addressed by these methods. Inthis paper, we present a unified end-to-end differentiable framework formulti-view, multi-frame hand tracking that directly predicts 3D hand pose inworld space. We demonstrate the benefits of end-to-end differentiabilty byextending our framework with downstream tasks such as jitter reduction andpinch prediction. To demonstrate the efficacy of our model, we further presenta new large-scale egocentric hand pose dataset that consists of both real andsynthetic data. Experiments show that our system trained on this datasethandles various challenging interactive motions, and has been successfullyapplied to real-time VR applications.
Multi-view hand pose tracking. 用VR眼镜的相机预测3D hand pose in world space. 用网络预测. 提出了一个数据集.
hand-pose@inproceedings{UmeTrack, title = {UmeTrack: Unified multi-view end-to-end hand tracking for VR}, author = {Han, Shangchen and Wu, Po-chen and Zhang, Yubo and Liu, Beibei and Zhang, Linguang and Wang, Zheng and Si, Weiguang and Zhang, Peizhao and Cai, Yujun and Hodan, Tomas and Cabezas, Randi and Tran, Luan and Akbay, Muzaffer and Yu, Tsz-Ho and Keskin, Cem and Wang, Robert}, year = {2022}, tags = {hand-pose}, sida = {Multi-view hand pose tracking. 用VR眼镜的相机预测3D hand pose in world space. 用网络预测. 提出了一个数据集.}, } - VIINTER: View Interpolation with Implicit Neural Representations of ImagesBrandon Yushan Feng, Susmija Jabbireddy, and Amitabh VarshneyIn 2022
We present VIINTER, a method for view interpolation by interpolating theimplicit neural representation (INR) of the captured images. We leverage thelearned code vector associated with each image and interpolate between thesecodes to achieve viewpoint transitions. We propose several techniques thatsignificantly enhance the interpolation quality. VIINTER signifies a new way toachieve view interpolation without constructing 3D structure, estimating cameraposes, or computing pixel correspondence. We validate the effectiveness ofVIINTER on several multi-view scenes with different types of camera layout andscene composition. As the development of INR of images (as opposed to surfaceor volume) has centered around tasks like image fitting and super-resolution,with VIINTER, we show its capability for view interpolation and offer apromising outlook on using INR for image manipulation tasks.
用INR和latent vectors记录多张图片, 通过插值latent vectors实现view interpolation.
view-synthesis@inproceedings{VIINTER, title = {VIINTER: View Interpolation with Implicit Neural Representations of Images}, author = {Feng, Brandon Yushan and Jabbireddy, Susmija and Varshney, Amitabh}, year = {2022}, tags = {view-synthesis}, sida = {用INR和latent vectors记录多张图片, 通过插值latent vectors实现view interpolation.}, } - nerf2nerf: Pairwise Registration of Neural Radiance FieldsLily Goli, Daniel Rebain, Sara Sabour, Animesh Garg, and Andrea TagliasacchiIn 2022
We introduce a technique for pairwise registration of neural fields thatextends classical optimization-based local registration (i.e. ICP) to operateon Neural Radiance Fields (NeRF) – neural 3D scene representations trainedfrom collections of calibrated images. NeRF does not decompose illumination andcolor, so to make registration invariant to illumination, we introduce theconcept of a ”surface field” – a field distilled from a pre-trained NeRFmodel that measures the likelihood of a point being on the surface of anobject. We then cast nerf2nerf registration as a robust optimization thatiteratively seeks a rigid transformation that aligns the surface fields of thetwo scenes. We evaluate the effectiveness of our technique by introducing adataset of pre-trained NeRF scenes – our synthetic scenes enable quantitativeevaluations and comparisons to classical registration techniques, while ourreal scenes demonstrate the validity of our technique in real-world scenarios.Additional results available at: https://nerf2nerf.github.io
Registration of neural radiance fields. 从nerf中提取surface fields, 然后求解两个surface fields的rigid transformation.
registration nerf@inproceedings{nerf2nerf, title = {nerf2nerf: Pairwise Registration of Neural Radiance Fields}, author = {Goli, Lily and Rebain, Daniel and Sabour, Sara and Garg, Animesh and Tagliasacchi, Andrea}, year = {2022}, tags = {registration, nerf}, sida = {Registration of neural radiance fields. 从nerf中提取surface fields, 然后求解两个surface fields的rigid transformation.}, } - FactorMatte: Redefining Video Matting for Re-Composition TasksZeqi Gu, Wenqi Xian, Noah Snavely, and Abe DavisIn 2022
We propose "factor matting", an alternative formulation of the video mattingproblem in terms of counterfactual video synthesis that is better suited forre-composition tasks. The goal of factor matting is to separate the contents ofvideo into independent components, each visualizing a counterfactual version ofthe scene where contents of other components have been removed. We show thatfactor matting maps well to a more general Bayesian framing of the mattingproblem that accounts for complex conditional interactions between layers.Based on this observation, we present a method for solving the factor mattingproblem that produces useful decompositions even for video with complexcross-layer interactions like splashes, shadows, and reflections. Our method istrained per-video and requires neither pre-training on external large datasets,nor knowledge about the 3D structure of the scene. We conduct extensiveexperiments, and show that our method not only can disentangle scenes withcomplex interactions, but also outperforms top methods on existing tasks suchas classical video matting and background subtraction. In addition, wedemonstrate the benefits of our approach on a range of downstream tasks. Pleaserefer to our project webpage for more details: https://factormatte.github.io
Factor matting of videos. 将video中的各部分内容decompose出来. 用一个网络预测图片中的各个component. 通过reconstruction loss训练网络. 通过foreground discriminator来regularize training.
matting@inproceedings{FactorMatte, title = {FactorMatte: Redefining Video Matting for Re-Composition Tasks}, author = {Gu, Zeqi and Xian, Wenqi and Snavely, Noah and Davis, Abe}, year = {2022}, tags = {matting}, sida = {Factor matting of videos. 将video中的各部分内容decompose出来. 用一个网络预测图片中的各个component. 通过reconstruction loss训练网络. 通过foreground discriminator来regularize training.}, } - TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from TextAditya Sanghi, Rao Fu, Vivian Liu, Karl Willis, Hooman Shayani, Amir Hosein Khasahmadi, Srinath Sridhar, and Daniel RitchieIn 2022
Language is one of the primary means by which we describe the 3D world aroundus. While rapid progress has been made in text-to-2D-image synthesis, similarprogress in text-to-3D-shape synthesis has been hindered by the lack of paired(text, shape) data. Moreover, extant methods for text-to-shape generation havelimited shape diversity and fidelity. We introduce TextCraft, a method toaddress these limitations by producing high-fidelity and diverse 3D shapeswithout the need for (text, shape) pairs for training. TextCraft achieves thisby using CLIP and using a multi-resolution approach by first generating in alow-dimensional latent space and then upscaling to a higher resolution,improving the fidelity of the generated shape. To improve shape diversity, weuse a discrete latent space which is modelled using a bidirectional transformerconditioned on the interchangeable image-text embedding space induced by CLIP.Moreover, we present a novel variant of classifier-free guidance, which furtherimproves the accuracy-diversity trade-off. Finally, we perform extensiveexperiments that demonstrate that TextCraft outperforms state-of-the-artbaselines.
Text-to-shape generation without training on paired data. 在一组3D shape上训练. 训练基于CLIP的image feature生成shape的网络. 从而实现基于CLIP的texture feature生成shape.
text-to-shape@inproceedings{TextCraft, title = {TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text}, author = {Sanghi, Aditya and Fu, Rao and Liu, Vivian and Willis, Karl and Shayani, Hooman and Khasahmadi, Amir Hosein and Sridhar, Srinath and Ritchie, Daniel}, year = {2022}, tags = {text-to-shape}, sida = {Text-to-shape generation without training on paired data. 在一组3D shape上训练. 训练基于CLIP的image feature生成shape的网络. 从而实现基于CLIP的texture feature生成shape.}, } -
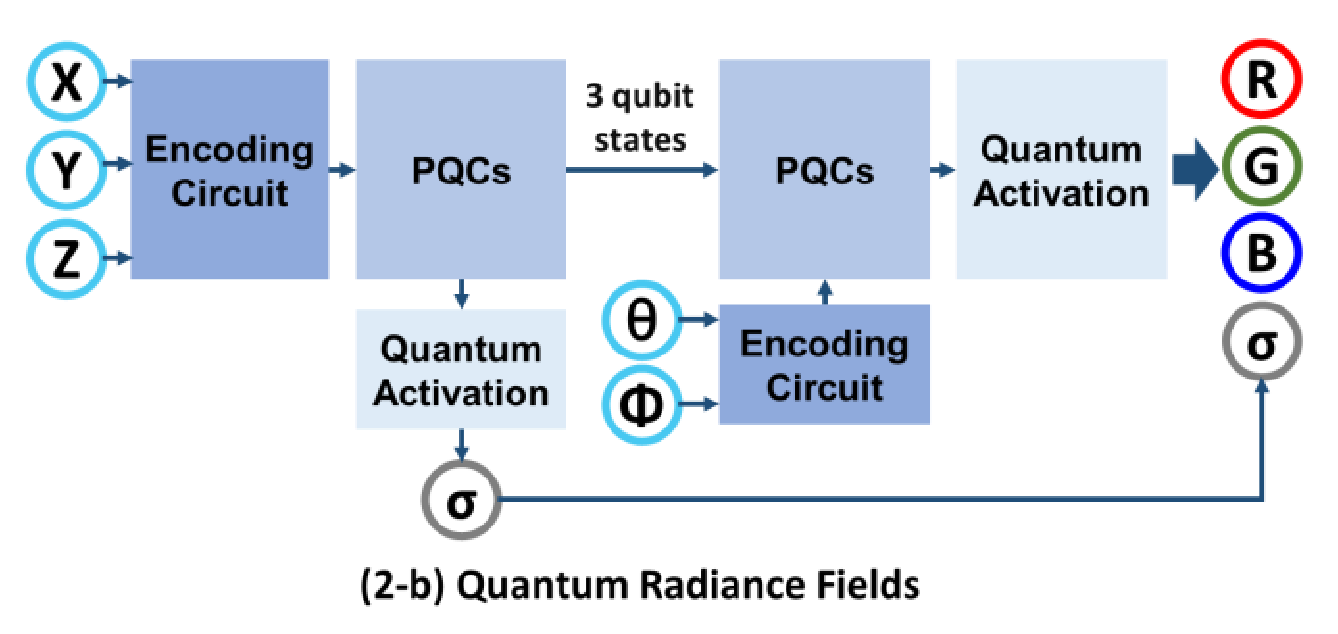 QRF: Implicit Neural Representations with Quantum Radiance FieldsYuanFu Yang, and Min SunIn 2022
QRF: Implicit Neural Representations with Quantum Radiance FieldsYuanFu Yang, and Min SunIn 2022Photorealistic rendering of real-world scenes is a tremendous challenge witha wide range of applications, including MR (Mixed Reality), and VR (MixedReality). Neural networks, which have long been investigated in the context ofsolving differential equations, have previously been introduced as implicitrepresentations for Photorealistic rendering. However, realistic renderingusing classic computing is challenging because it requires time-consumingoptical ray marching, and suffer computational bottlenecks due to the curse ofdimensionality. In this paper, we propose Quantum Radiance Fields (QRF), whichintegrate the quantum circuit, quantum activation function, and quantum volumerendering for implicit scene representation. The results indicate that QRF notonly takes advantage of the merits of quantum computing technology such as highspeed, fast convergence, and high parallelism, but also ensure high quality ofvolume rendering.
通过quantum techniques加速nerf.
nerf-speed@inproceedings{QRF, title = {QRF: Implicit Neural Representations with Quantum Radiance Fields}, author = {Yang, YuanFu and Sun, Min}, year = {2022}, tags = {nerf-speed}, sida = {通过quantum techniques加速nerf.}, } -
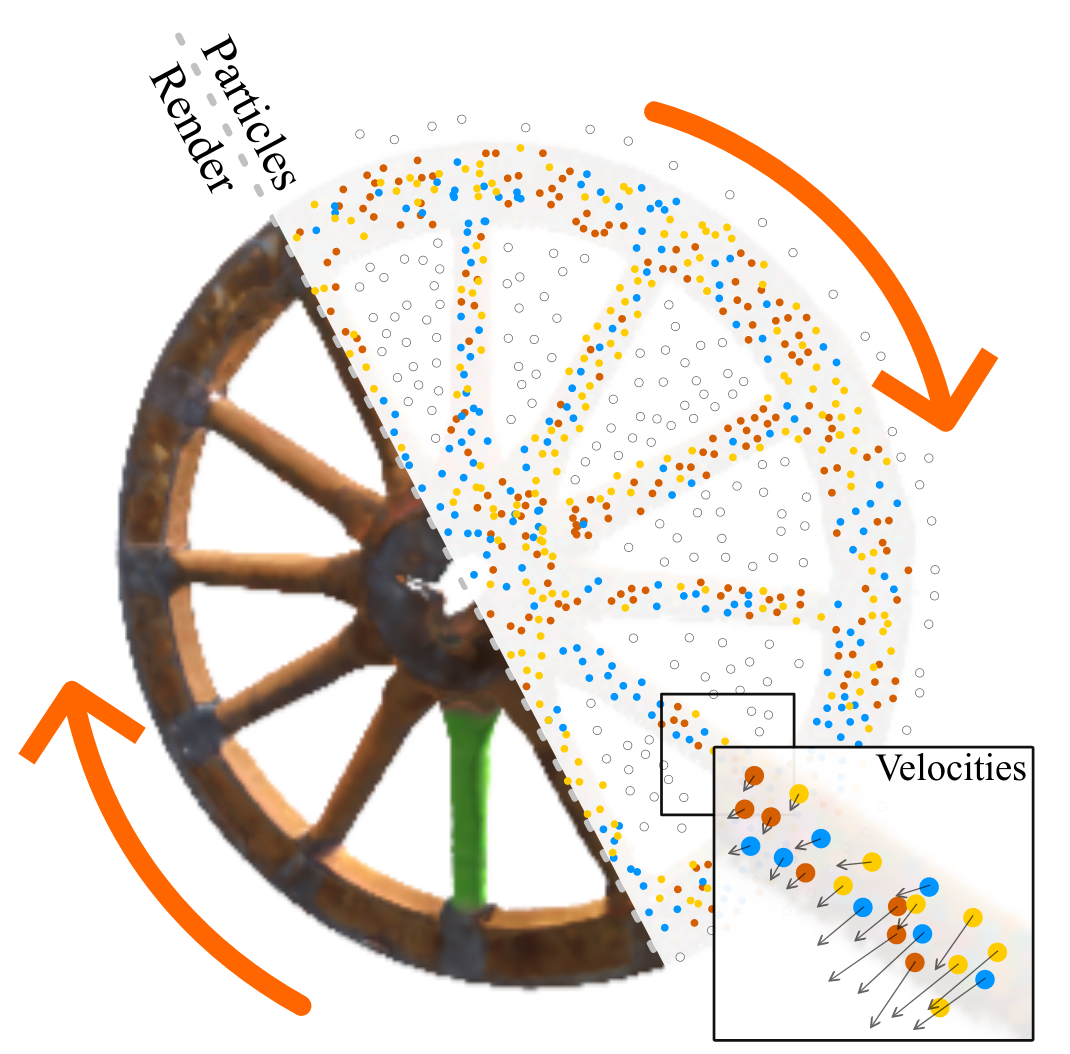 ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic ScenesJad Abou-Chakra, Feras Dayoub, and Niko SünderhaufIn 2022
ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic ScenesJad Abou-Chakra, Feras Dayoub, and Niko SünderhaufIn 2022Neural Radiance Fields (NeRFs) learn implicit representations of - typicallystatic - environments from images. Our paper extends NeRFs to handle dynamicscenes in an online fashion. We propose ParticleNeRF that adapts to changes inthe geometry of the environment as they occur, learning a new up-to-daterepresentation every 350 ms. ParticleNeRF can represent the current state ofdynamic environments with much higher fidelity as other NeRF frameworks. Toachieve this, we introduce a new particle-based parametric encoding, whichallows the intermediate NeRF features - now coupled to particles in space - tomove with the dynamic geometry. This is possible by backpropagating thephotometric reconstruction loss into the position of the particles. Theposition gradients are interpreted as particle velocities and integrated intopositions using a position-based dynamics (PBS) physics system. Introducing PBSinto the NeRF formulation allows us to add collision constraints to theparticle motion and creates future opportunities to add other movement priorsinto the system, such as rigid and deformable body
提出了particle-based parametric encoding, 将features anchor在dynamic geometry, 实现view synthesis of dynamic scenes. 用position-based dynamics physics system表示dynamic geometry.
view-synthesis dynamic-scene@inproceedings{ParticleNeRF, title = {ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic Scenes}, author = {Abou-Chakra, Jad and Dayoub, Feras and Sünderhauf, Niko}, year = {2022}, tags = {view-synthesis, dynamic-scene}, sida = {提出了particle-based parametric encoding, 将features anchor在dynamic geometry, 实现view synthesis of dynamic scenes. 用position-based dynamics physics system表示dynamic geometry.}, } - Editable Indoor Lighting EstimationHenrique Weber, Mathieu Garon, and Jean-François LalondeIn 2022
We present a method for estimating lighting from a single perspective imageof an indoor scene. Previous methods for predicting indoor illumination usuallyfocus on either simple, parametric lighting that lack realism, or on richerrepresentations that are difficult or even impossible to understand or modifyafter prediction. We propose a pipeline that estimates a parametric light thatis easy to edit and allows renderings with strong shadows, alongside with anon-parametric texture with high-frequency information necessary for realisticrendering of specular objects. Once estimated, the predictions obtained withour model are interpretable and can easily be modified by an artist/user with afew mouse clicks. Quantitative and qualitative results show that our approachmakes indoor lighting estimation easier to handle by a casual user, while stillproducing competitive results.
提出了一种parametric light, 支持realistic rendering和编辑.
editable lighting@inproceedings{EditableIndoorLight, title = {Editable Indoor Lighting Estimation}, author = {Weber, Henrique and Garon, Mathieu and Lalonde, Jean-François}, year = {2022}, tags = {editable, lighting}, sida = {提出了一种parametric light, 支持realistic rendering和编辑.}, } -
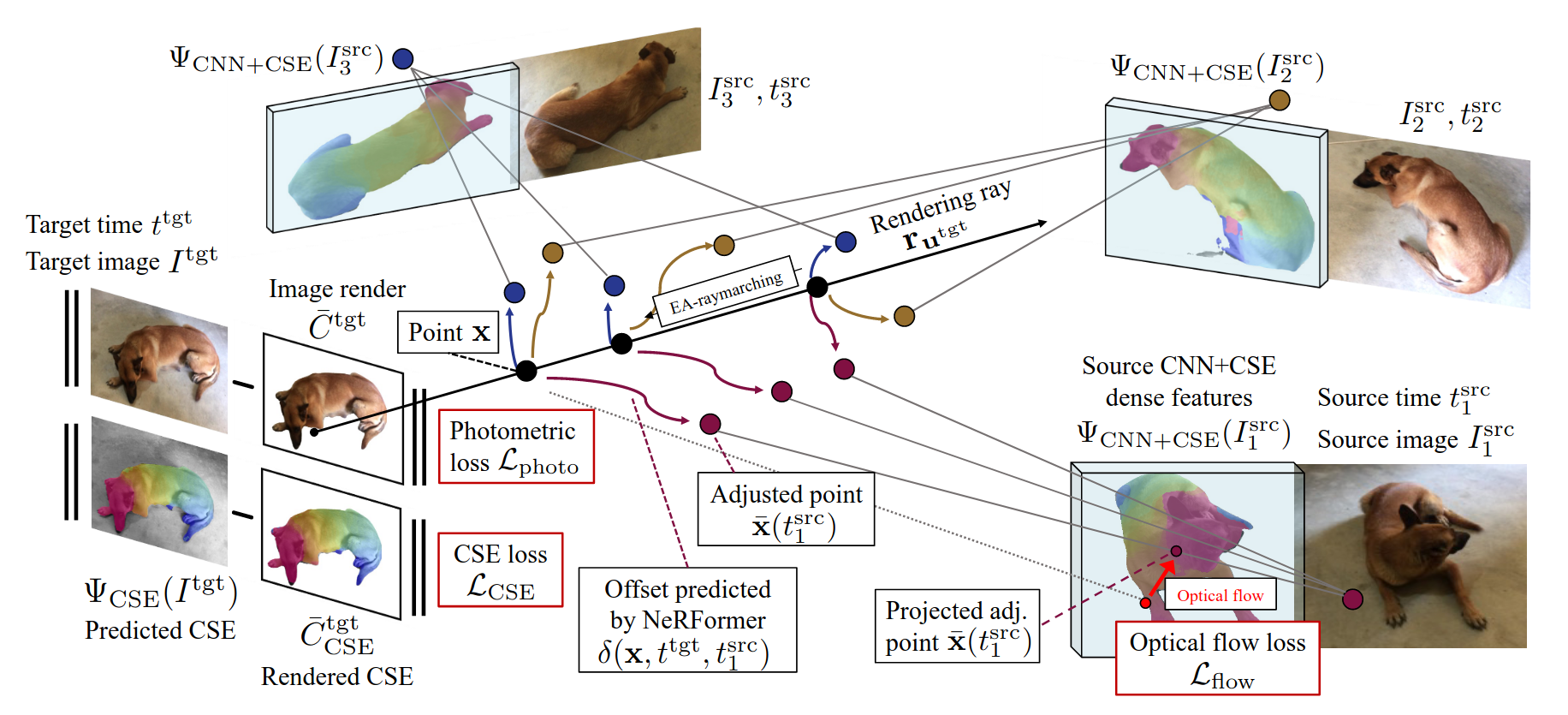 Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesSamarth Sinha, Roman Shapovalov, Jeremy Reizenstein, Ignacio Rocco, Natalia Neverova, Andrea Vedaldi, and David NovotnyIn 2022
Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable CategoriesSamarth Sinha, Roman Shapovalov, Jeremy Reizenstein, Ignacio Rocco, Natalia Neverova, Andrea Vedaldi, and David NovotnyIn 2022Obtaining photorealistic reconstructions of objects from sparse views isinherently ambiguous and can only be achieved by learning suitablereconstruction priors. Earlier works on sparse rigid object reconstructionsuccessfully learned such priors from large datasets such as CO3D. In thispaper, we extend this approach to dynamic objects. We use cats and dogs as arepresentative example and introduce Common Pets in 3D (CoP3D), a collection ofcrowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of thefirst large-scale datasets for benchmarking non-rigid 3D reconstruction "in thewild". We also propose Tracker-NeRF, a method for learning 4D reconstructionfrom our dataset. At test time, given a small number of video frames of anunseen object, Tracker-NeRF predicts the trajectories of its 3D points andgenerates new views, interpolating viewpoint and time. Results on CoP3D revealsignificantly better non-rigid new-view synthesis performance than existingbaselines.
提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.
monocular-video deformable-objects view-synthesis@inproceedings{Common_Pets, title = {Common Pets in 3D: Dynamic New-View Synthesis of Real-Life Deformable Categories}, author = {Sinha, Samarth and Shapovalov, Roman and Reizenstein, Jeremy and Rocco, Ignacio and Neverova, Natalia and Vedaldi, Andrea and Novotny, David}, year = {2022}, tags = {monocular-video, deformable-objects, view-synthesis}, sida = {提出了一个deformable objects的数据集, 用于训练一个网络, 从几帧图像中重建出deformable objects.}, } - Learning Visual Locomotion with Cross-Modal SupervisionAntonio Loquercio, Ashish Kumar, and Jitendra MalikIn 2022
In this work, we show how to learn a visual walking policy that only uses amonocular RGB camera and proprioception. Since simulating RGB is hard, wenecessarily have to learn vision in the real world. We start with a blindwalking policy trained in simulation. This policy can traverse some terrains inthe real world but often struggles since it lacks knowledge of the upcominggeometry. This can be resolved with the use of vision. We train a visual modulein the real world to predict the upcoming terrain with our proposed algorithmCross-Modal Supervision (CMS). CMS uses time-shifted proprioception tosupervise vision and allows the policy to continually improve with morereal-world experience. We evaluate our vision-based walking policy over adiverse set of terrains including stairs (up to 19cm high), slippery slopes(inclination of 35 degrees), curbs and tall steps (up to 20cm), and complexdiscrete terrains. We achieve this performance with less than 30 minutes ofreal-world data. Finally, we show that our policy can adapt to shifts in thevisual field with a limited amount of real-world experience. Video results andcode at https://antonilo.github.io/vision_locomotion/.
在walking robotics中加入了visual module, 学习处理upcoming geometry. 通过proprioception在real world中训练这个visual module.
visual-locomotion@inproceedings{Learning_Visual_Locomotion, title = {Learning Visual Locomotion with Cross-Modal Supervision}, author = {Loquercio, Antonio and Kumar, Ashish and Malik, Jitendra}, year = {2022}, tags = {visual-locomotion}, sida = {在walking robotics中加入了visual module, 学习处理upcoming geometry. 通过proprioception在real world中训练这个visual module.}, }
2021
-
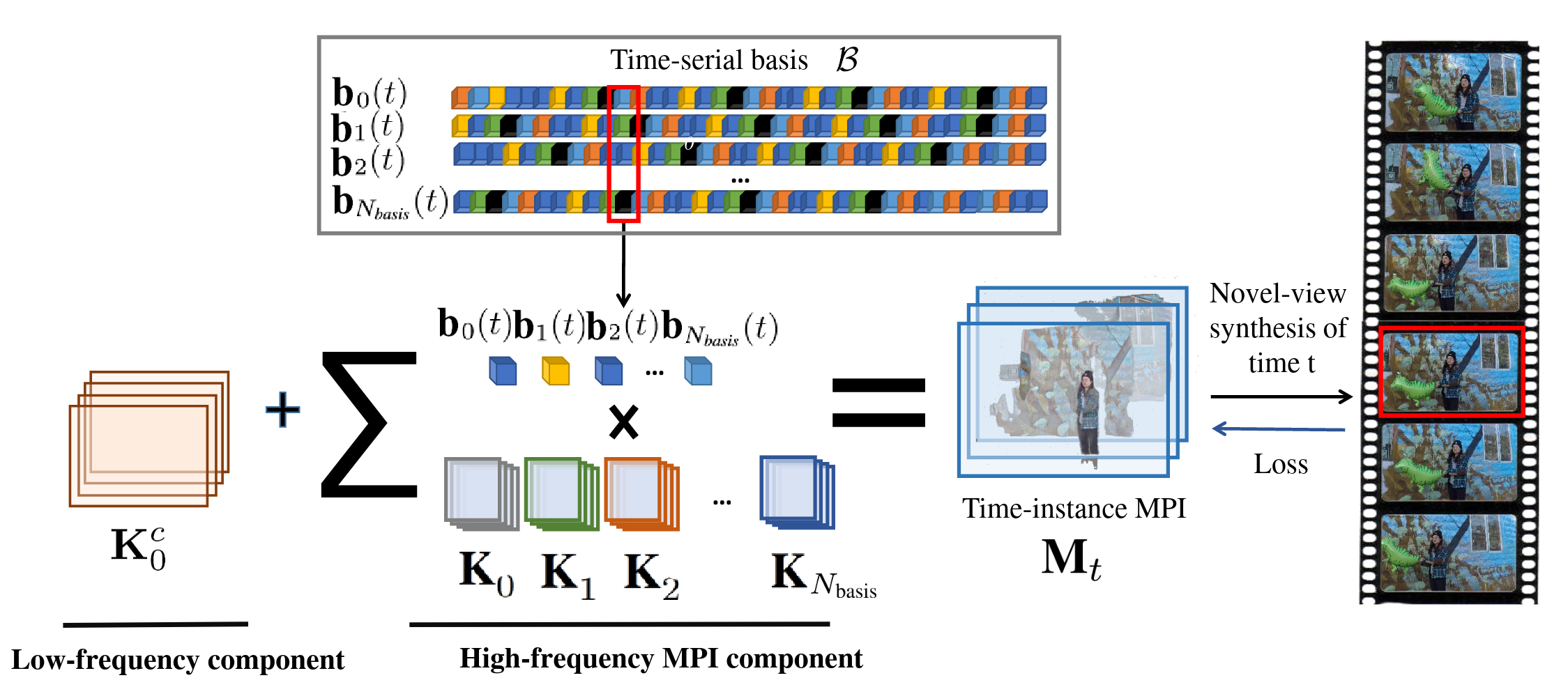 Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis LearningWenpeng Xing, and Jie ChenIn 2021
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis LearningWenpeng Xing, and Jie ChenIn 2021Novel view synthesis of static scenes has achieved remarkable advancements inproducing photo-realistic results. However, key challenges remain for immersiverendering of dynamic scenes. One of the seminal image-based rendering method,the multi-plane image (MPI), produces high novel-view synthesis quality forstatic scenes. But modelling dynamic contents by MPI is not studied. In thispaper, we propose a novel Temporal-MPI representation which is able to encodethe rich 3D and dynamic variation information throughout the entire video ascompact temporal basis and coefficients jointly learned. Time-instance MPI forrendering can be generated efficiently using mini-seconds by linearcombinations of temporal basis and coefficients from Temporal-MPI. Thusnovel-views at arbitrary time-instance will be able to be rendered viaTemporal-MPI in real-time with high visual quality. Our method is trained andevaluated on Nvidia Dynamic Scene Dataset. We show that our proposed Temporal-MPI is much faster and more compact compared with other state-of-the-artdynamic scene modelling methods.
构建一组MPI basis和coefficients, 通过linear combinations得到每一帧的MPI, 实现dynamic view synthesis.
view-synthesis dynamic-scene@inproceedings{Temporal-MPI, title = {Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning}, author = {Xing, Wenpeng and Chen, Jie}, year = {2021}, tags = {view-synthesis, dynamic-scene}, sida = {构建一组MPI basis和coefficients, 通过linear combinations得到每一帧的MPI, 实现dynamic view synthesis.}, }